

HyperWrites grundare och VD Matt Shumer meddelade att hans nya modell, Reflection 70B, använder ett enkelt trick för att lösa LLM-hallucinationer och levererar imponerande benchmarkresultat som slår större och till och med slutna modeller som GPT-4o.
Shumer samarbetade med Glaive, leverantör av syntetiska data, för att skapa den nya modellen som baseras på Metas Llama 3.1-70B Instruct-modell.
I lanseringsmeddelandet på Hugging Face sa Shumer. "Reflection Llama-3.1 70B är (för närvarande) världens bästa LLM med öppen källkod, tränad med en ny teknik som kallas Reflection-Tuning som lär en LLM att upptäcka misstag i sitt resonemang och korrigera kursen."
Om Shumer hittade ett sätt att lösa frågan om AI-hallucinationer så skulle det vara otroligt. De riktmärken han delade verkar tyda på att Reflection 70B ligger långt före andra modeller.
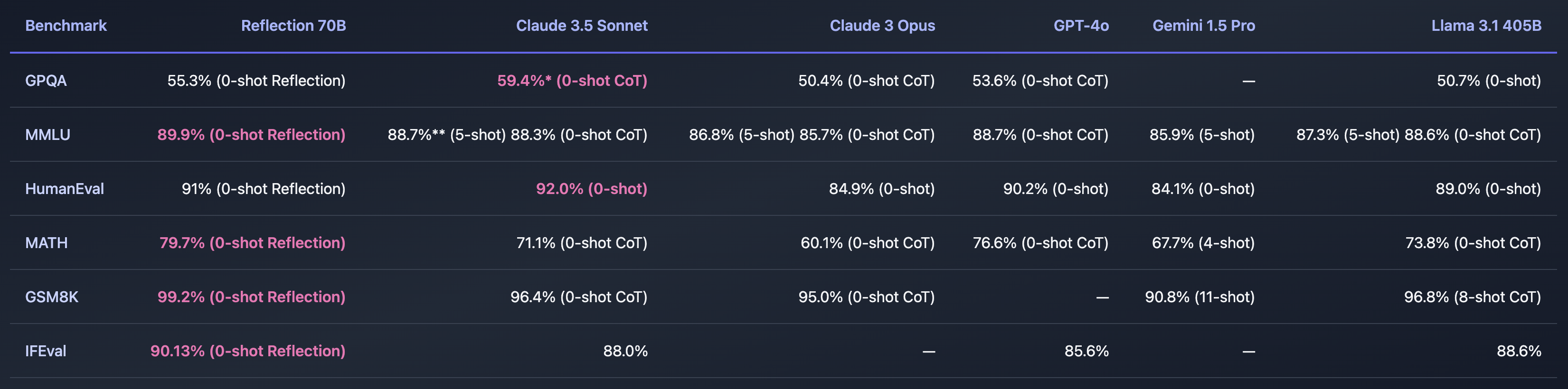
Modellens namn syftar på dess förmåga att självkorrigera sig under slutledningsprocessen. Shumer avslöjar inte för mycket, men förklarar att modellen reflekterar över sitt första svar på en fråga och lämnar ut det först när den är övertygad om att det är korrekt.
Shumer säger att en 405B-version av Reflection är på gång och att den kommer att slå andra modeller, inklusive GPT-4o, med häpnad när den presenteras nästa vecka.
Är Reflection 70B en bluff?
Är allt detta för bra för att vara sant? Reflection 70B finns tillgänglig för nedladdning på Huging Face men tidiga testare kunde inte upprepa den imponerande prestanda som Shumers benchmarks visade.
Den Lekplats för reflektion låter dig prova modellen men säger att på grund av hög efterfrågan är demot tillfälligt nere. Frågeförslagen "Räkna 'r' i jordgubbe" och "9.11 vs 9.9" antyder att modellen får dessa knepiga uppmaningar rätt. Men vissa användare hävdar att Reflection har anpassats specifikt för att svara på dessa uppmaningar.
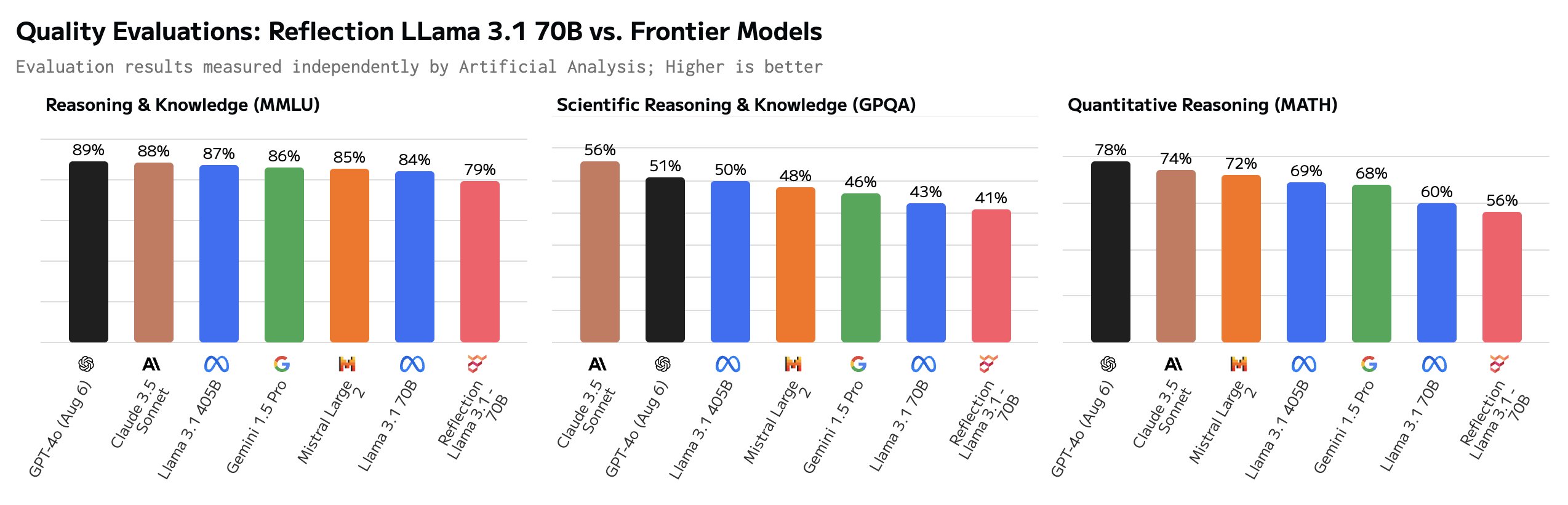
Vissa användare ifrågasatte de imponerande riktmärkena. GSM8K på över 99% såg särskilt misstänkt ut.
Hej Matt! Det här är superintressant, men jag är ganska förvånad över att se en GSM8k-poäng på över 99%. Min förståelse är att det är troligt att mer än 1% av GSM8k är felmärkt (det rätta svaret är faktiskt fel)!
- Hugh Zhang (@hughbzhang) 5 september 2024
Några av de sanna svaren i GSM8K-datasetet är faktiskt felaktiga. Med andra ord var det enda sättet att få över 99% poäng på GSM8K att ge samma felaktiga svar på dessa problem.
Efter några tester säger användare att Reflection faktiskt är sämre än Llama 3.1 och att det faktiskt bara var Llama 3 med LoRA-tuning tillämpad.
Som svar på den negativa feedbacken publicerade Shumer en förklaring på X och sa: "Snabb uppdatering - vi laddade upp vikterna igen men det finns fortfarande ett problem. Vi började precis träna igen för att eliminera eventuella problem. Borde vara klart snart."
Shumer förklarade att det fanns ett problem med API:et och att de arbetade på det. Under tiden gav han tillgång till ett hemligt, privat API så att tvivlare kunde prova Reflection medan de arbetade med fixen.
Och det är där hjulen verkar lossna, eftersom en noggrann uppmaning verkar visa att API: et egentligen bara är en Claude 3.5 Sonnet-omslag.
"Reflection API" är en sonnet 3.5 wrapper med prompt. Och de döljer den för närvarande genom att filtrera bort strängen "claude".https://t.co/c4Oj8Y3Ol1 https://t.co/k0ECeo9a4i pic.twitter.com/jTm2Q85Q7b
- Joseph (@RealJosephus) 8 september 2024
Efterföljande testning hade API enligt uppgift returnerat utgångar från Llama och GPT-4o. Shumer insisterar på att de ursprungliga resultaten är korrekta och att de arbetar med att fixa den nedladdningsbara modellen.
Är skeptikerna lite för tidiga med att kalla Shumer för en bedragare? Kanske var lanseringen bara dåligt hanterad och Reflection 70B verkligen är en banbrytande open source-modell. Eller så är det ännu ett exempel på AI-hype för att skaffa riskkapital från investerare som letar efter nästa stora grej inom AI.
Vi får vänta en dag eller två för att se hur det här utvecklas.



