

Benchmarks har svårt att hänga med i utvecklingen av AI-modellernas kapacitet och projektet Humanity's Last Exam vill ha din hjälp att åtgärda detta.
Projektet är ett samarbete mellan Center for AI Safety (CAIS) och AI-dataföretaget Scale AI. Projektet syftar till att mäta hur nära vi är att uppnå AI-system på expertnivå, något som befintliga riktmärken inte är kapabla till.
OpenAI och CAIS utvecklade det populära riktmärket MMLU (Massive Multitask Language Understanding) 2021. På den tiden, säger CAIS, "presterade AI-system inte bättre än slumpmässigt."
Den imponerande prestandan hos OpenAI:s o1-modell har "förstört de mest populära benchmarks för resonemang", enligt Dan Hendrycks, verkställande direktör för CAIS.
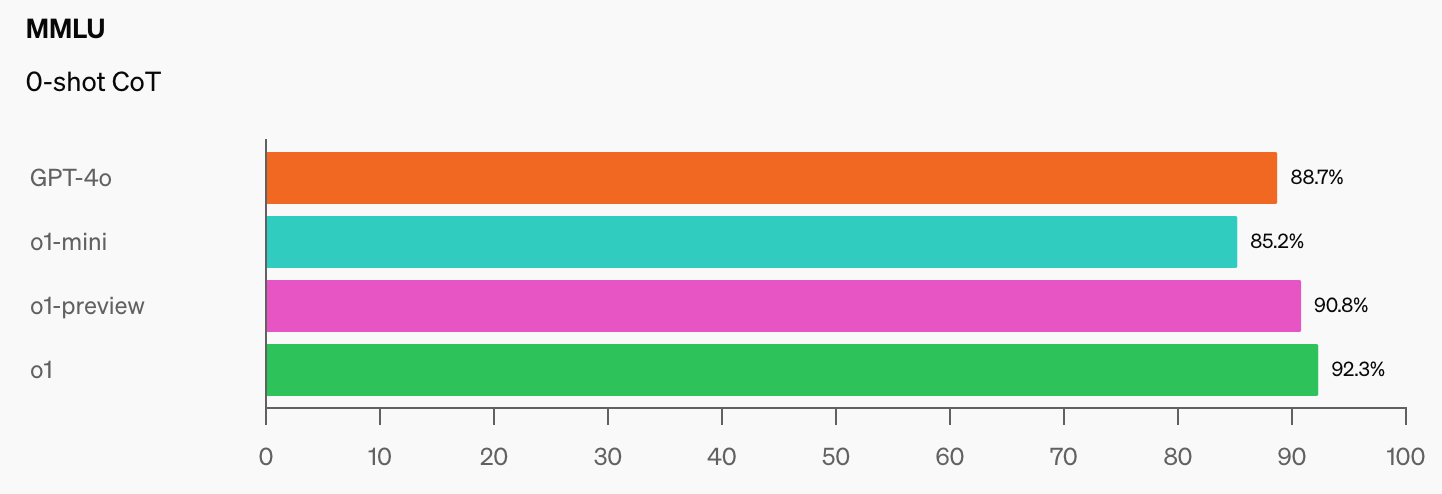
När AI-modeller når 100% på MMLU, hur ska vi då mäta dem? CAIS säger "Befintliga tester har nu blivit för enkla och vi kan inte längre följa AI-utvecklingen på ett bra sätt, eller hur långt de är från att bli expertnivå."
När man ser hur mycket bättre benchmarkresultaten blev när o1 lade till de redan imponerande GPT-4o-siffrorna, kommer det inte att dröja länge innan en AI-modell klarar MMLU.
Detta är objektivt sant. pic.twitter.com/gorahh86ee
- Ethan Mollick (@emollick) 17 september 2024
Humanity's Last Exam ber människor att skicka in frågor som verkligen skulle förvåna dig om en AI-modell levererade rätt svar. De vill ha examensfrågor på doktorandnivå, inte typen "hur många R i Strawberry" som snubblar upp vissa modeller.
Scale förklarade att "När befintliga tester blir för lätta förlorar vi förmågan att skilja mellan AI-system som kan klara högskoleprovet och de som verkligen kan bidra till spetsforskning och problemlösning."
Om du har en originell fråga som kan få en avancerad AI-modell att tappa fattningen kan du få ditt namn tillagt som medförfattare till projektets artikel och ta del av en pool på $500.000 som kommer att delas ut till de bästa frågorna.
För att ge dig en uppfattning om vilken nivå projektet siktar på förklarade Scale att "om en slumpmässigt utvald student kan förstå vad som efterfrågas är det sannolikt för lätt för dagens och morgondagens främsta LLM:er".
Det finns några intressanta restriktioner för vilka typer av frågor som kan skickas in. De vill inte ha något som rör kemiska, biologiska, radiologiska eller nukleära vapen eller cybervapen som används för att angripa kritisk infrastruktur.
Om du tror att du har en fråga som uppfyller kraven kan du skicka in den här.



