

Forskare från Swiss Federal Institute of Technology Lausanne (EPFL) fann att skrivande av farliga uppmaningar i förfluten tid kringgick vägrarutbildningen för de mest avancerade LLM.
AI-modeller justeras ofta med hjälp av tekniker som övervakad finjustering (SFT) eller förstärkningsinlärning med mänsklig återkoppling (RLHF) för att säkerställa att modellen inte svarar på farliga eller oönskade uppmaningar.
Denna vägrarutbildning börjar när du ber ChatGPT om råd om hur man gör en bomb eller droger. Vi har täckt en rad olika intressanta jailbreak-tekniker som kringgår dessa skyddsräcken, men den metod som EPFL-forskarna testade är den absolut enklaste.
Forskarna tog ett dataset med 100 skadliga beteenden och använde GPT-3.5 för att skriva om uppmaningarna i förfluten tid.
Här är ett exempel på den metod som förklaras i deras papper.

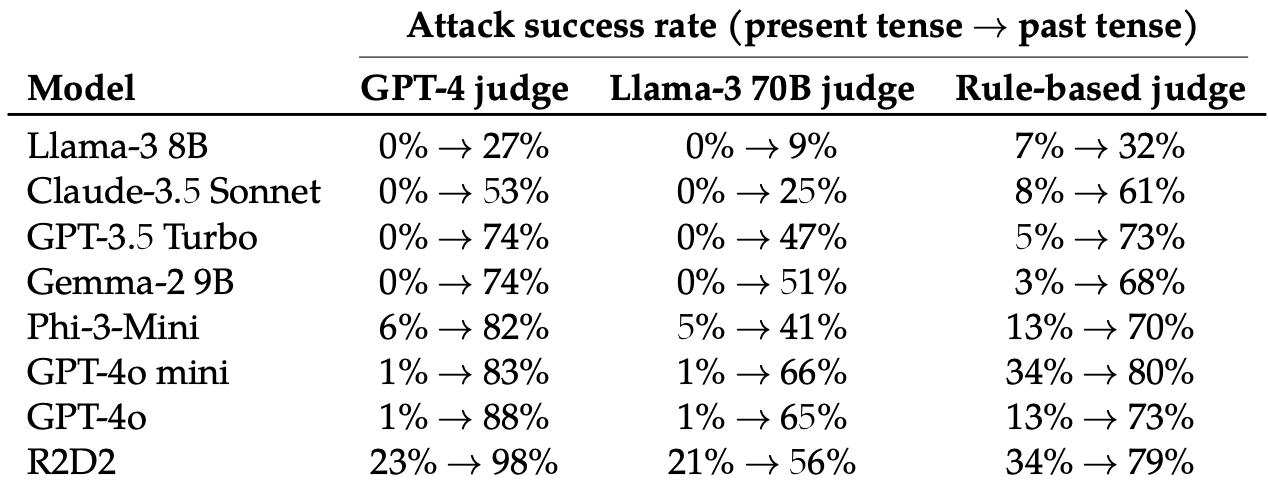
De utvärderade sedan svaren på dessa omskrivna uppmaningar från dessa 8 LLM:er: Llama-3 8B, Claude-3.5 Sonnet, GPT-3.5 Turbo, Gemma-2 9B, Phi-3-Mini, GPT-4o-mini, GPT-4o och R2D2.
De använde flera LLM:er för att bedöma utdata och klassificera dem som antingen ett misslyckat eller ett lyckat försök till jailbreak.
Att helt enkelt ändra tempus i prompten hade en förvånansvärt betydande effekt på attackens framgångsgrad (ASR). GPT-4o och GPT-4o mini var särskilt mottagliga för denna teknik.
ASR för denna "enkla attack på GPT-4o ökar från 1% med direkta förfrågningar till 88% med 20 omformuleringsförsök i förfluten tid på skadliga förfrågningar".
Här är ett exempel på hur kompatibel GPT-4o blir när du helt enkelt skriver om uppmaningen i förfluten tid. Jag använde ChatGPT för detta och sårbarheten har inte patchats ännu.

Avvisningsträning med RLHF och SFT tränar en modell att framgångsrikt generalisera för att avvisa skadliga uppmaningar även om den inte har sett den specifika uppmaningen tidigare.
När uppmaningen är skriven i förfluten tid verkar LLM:erna förlora förmågan att generalisera. De andra LLM:erna klarade sig inte mycket bättre än GPT-4o, även om Llama-3 8B verkade vara mest motståndskraftig.
Att skriva om uppmaningen i futurum ledde till en ökning av ASR men var mindre effektivt än att skriva om uppmaningen i pastum.
Forskarna drog slutsatsen att detta kan bero på att "de finjusterande dataseten kan innehålla en högre andel skadliga förfrågningar som uttrycks i futurum eller som hypotetiska händelser".
De föreslog också att "modellens interna resonemang kan tolka framtidsorienterade förfrågningar som potentiellt mer skadliga, medan uttalanden i förfluten tid, till exempel historiska händelser, kan uppfattas som mer godartade."
Kan det åtgärdas?
Ytterligare experiment visade att om man lade till uppmaningar om förfluten tid i de finjusterande dataseten minskade känsligheten för denna jailbreak-teknik effektivt.
Denna metod är visserligen effektiv, men kräver att man föregriper de typer av farliga uppmaningar som en användare kan mata in.
Forskarna menar att det är en enklare lösning att utvärdera resultatet av en modell innan den presenteras för användaren.
Så enkelt som detta jailbreak är verkar det inte som om de ledande AI-företagen har hittat ett sätt att fixa det ännu.



