

I en studie från University of Oxford har man utvecklat ett sätt att testa när språkmodeller är "osäkra" på sin output och riskerar att hallucinera.
AI-"hallucinationer" avser ett fenomen där stora språkmodeller (LLM) genererar flytande och trovärdiga svar som inte är sanningsenliga eller konsekventa.
Hallucinationer är svåra - om inte omöjliga - att skilja från AI-modeller. AI-utvecklare som OpenAI, Google och Anthropic har alla medgett att hallucinationer sannolikt kommer att förbli en biprodukt av att interagera med AI.
Som Dr. Sebastian Farquhar, en av studiens författare, förklarar i ett blogginlägg"LLM:er är mycket skickliga på att säga samma sak på många olika sätt, vilket kan göra det svårt att avgöra när de är säkra på ett svar och när de bokstavligen bara hittar på något."
Cambridge Dictionary har till och med lagt till en AI-relaterad definition av ordet år 2023 och utsåg det till "Årets ord".
Detta University of Oxford studie, publicerad i Nature, försöker svara på hur vi kan upptäcka när det är mest sannolikt att dessa hallucinationer inträffar.
Den introducerar ett begrepp som kallas "semantisk entropi", som mäter osäkerheten i en LLM:s resultat på betydelsenivå snarare än bara de specifika ord eller fraser som används.
Genom att beräkna den semantiska entropin i en LLM:s svar kan forskarna uppskatta modellens förtroende för sina utdata och identifiera tillfällen då den sannolikt hallucinerar.
Semantisk entropi i LLM förklaras
Semantisk entropi, enligt studiens definition, mäter osäkerheten eller inkonsekvensen i innebörden av en LLM:s svar. Det hjälper till att upptäcka när en LLM kanske hallucinerar eller genererar otillförlitlig information.
I enklare termer mäter semantisk entropi hur "förvirrad" en LLM:s utdata är.
LLM kommer sannolikt att ge tillförlitlig information om betydelsen av dess resultat är nära relaterad och konsekvent. Men om betydelserna är utspridda och inkonsekventa är det en varningssignal om att LLM kan hallucinera eller generera felaktig information.
Så här fungerar det:
- Forskarna har aktivt uppmanat LLM att generera flera möjliga svar på samma fråga. Detta uppnås genom att mata frågan till LLM flera gånger, varje gång med ett annat slumpmässigt frö eller en liten variation i inmatningen.
- Semantisk entropi granskar svaren och grupperar dem med samma underliggande innebörd, även om de använder olika ord eller formuleringar.
- Om LLM är säker på svaret bör dess svar ha liknande innebörd, vilket resulterar i en låg semantisk entropipoäng. Detta tyder på att LLM:n förstår informationen på ett tydligt och konsekvent sätt.
- Men om LLM är osäker eller förvirrad kommer svaren att ha en större variation av betydelser, varav vissa kan vara inkonsekventa eller orelaterade till frågan. Detta resulterar i en hög semantisk entropipoäng, vilket indikerar att LLM kan hallucinera eller generera otillförlitlig information.
För att utvärdera dess effektivitet tillämpade forskarna semantisk entropi på en rad olika frågor och svarsuppgifter. Detta omfattade riktmärken som triviafrågor, läsförståelse, ordproblem och biografier.
Överlag överträffade semantisk entropi befintliga metoder när det gällde att upptäcka när en LLM sannolikt skulle generera ett felaktigt eller inkonsekvent svar.
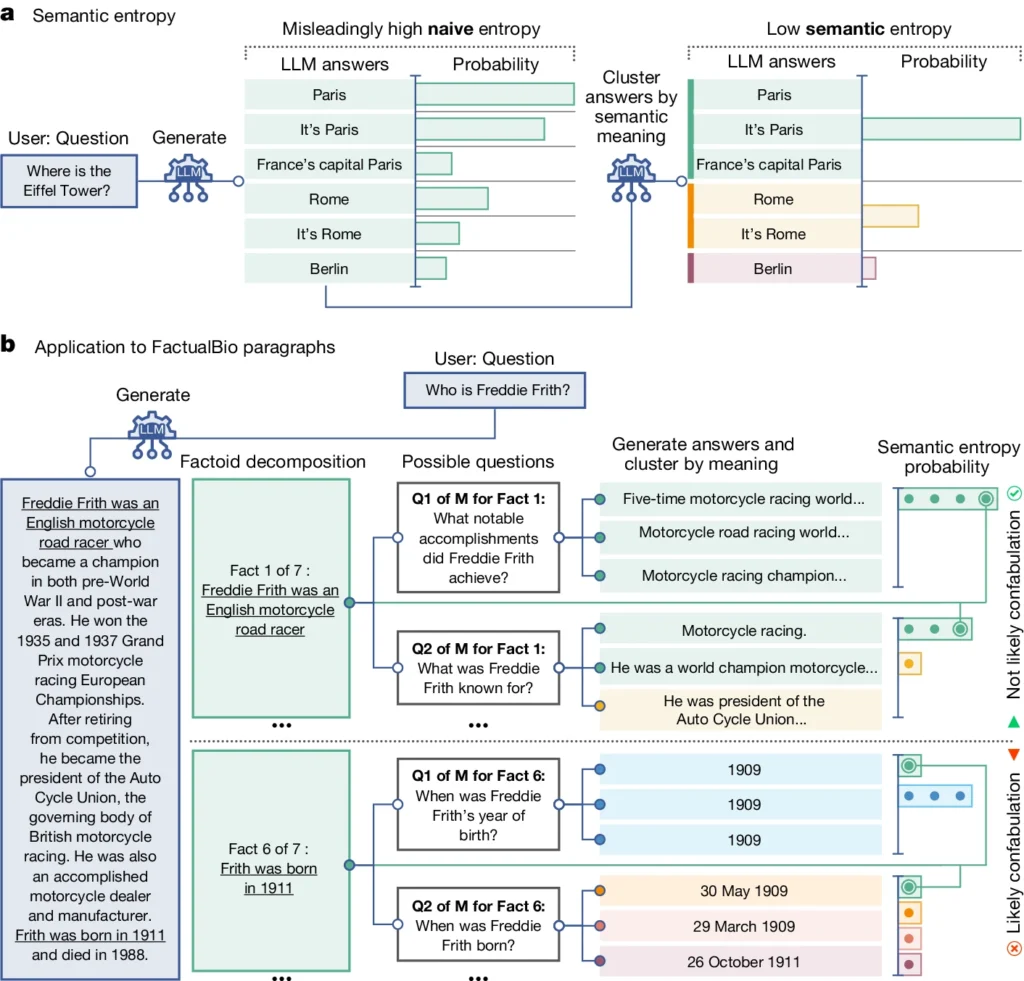
I diagrammet ovan kan du se hur vissa frågor får LLM att generera ett konfabulerat (felaktigt, hallucinatoriskt) svar. Den ger t.ex. en födelsedag och födelsemånad för frågorna längst ned i diagrammet när den information som krävs för att besvara dem inte fanns med i den ursprungliga informationen.
Konsekvenser av att upptäcka hallucinationer
Detta arbete kan bidra till att förklara hallucinationer och göra LLM:er mer tillförlitliga och trovärdiga.
Genom att tillhandahålla ett sätt att upptäcka när en LLM är osäker eller benägen att hallucinera banar semantisk entropi väg för att använda dessa AI-verktyg i domäner med höga insatser där faktakorrekthet är avgörande, som sjukvård, juridik och ekonomi.
Felaktiga resultat kan få potentiellt katastrofala följder när de påverkar situationer med höga insatser, vilket visats av vissa misslyckad prediktiv polisverksamhet och sjukvårdssystem.
Men det är också viktigt att komma ihåg att hallucinationer bara är en typ av fel som LLM:er kan göra.
Som Dr. Farquhar förklarar: "Om en LLM gör konsekventa misstag kommer den här nya metoden inte att fånga upp det. De farligaste AI-misslyckandena inträffar när ett system gör något dåligt, men är självsäkert och systematiskt. Det finns fortfarande mycket arbete kvar att göra."
Oxford-teamets semantiska entropimetod utgör dock ett stort steg framåt när det gäller vår förmåga att förstå och mildra begränsningarna i AI-språkmodeller.
Genom att tillhandahålla ett objektivt sätt att upptäcka dem kommer vi närmare en framtid där vi kan utnyttja AI:s potential och samtidigt se till att den förblir ett pålitligt och trovärdigt verktyg i mänsklighetens tjänst.



