

Google DeepMind-forskare utvecklade NATURAL PLAN, ett riktmärke för att utvärdera LLM:ers förmåga att planera verkliga uppgifter baserat på naturliga språkmeddelanden.
Nästa steg i utvecklingen av AI är att låta den lämna en chattplattform och ta på sig rollen som agent för att slutföra uppgifter på olika plattformar för vår räkning. Men det är svårare än det låter.
Planeringsuppgifter som att schemalägga ett möte eller sammanställa en semesterplan kan verka enkla för oss. Människor är bra på att resonera sig fram genom flera steg och förutse om ett tillvägagångssätt kommer att leda till att det önskade målet uppnås eller inte.
Du kanske tycker att det är lätt, men även de bästa AI-modellerna kämpar med planering. Kan vi jämföra dem för att se vilken LLM som är bäst på att planera?
Benchmarken NATURAL PLAN testar LLM:er på 3 planeringsuppgifter:
- Planering av resan - Planering av en resplan med hänsyn till flyg och destination
- Planering av möten - Schemalägga möten med flera vänner på olika platser
- Schemaläggning av kalender - Schemalägga arbetsmöten mellan flera personer utifrån befintliga scheman och olika begränsningar
Experimentet inleddes med några få uppmaningar där modellerna fick 5 exempel på uppmaningar och motsvarande korrekta svar. Därefter fick de planeringsuppmaningar av varierande svårighetsgrad.
Här är ett exempel på en uppmaning och en lösning som gavs som exempel till modellerna:

Resultat
Forskarna testade GPT-3.5, GPT-4, GPT-4o, Gemini 1.5 Flash, och Gemini 1,5 Prooch ingen av dem klarade sig särskilt bra i dessa tester.
Resultaten måste dock ha gått bra på DeepMind-kontoret eftersom Gemini 1.5 Pro kom ut på topp.

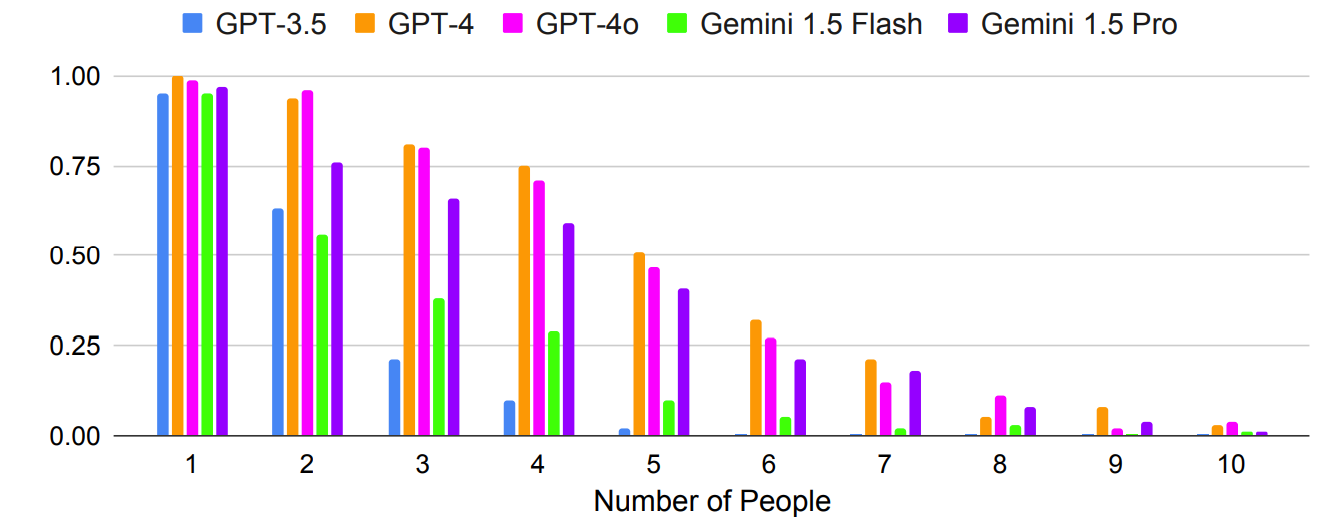
Som väntat blev resultaten exponentiellt sämre med mer komplexa uppmaningar där antalet personer eller städer ökades. Titta till exempel på hur snabbt noggrannheten försämrades när fler personer lades till i testet för mötesplanering.
Kan "multi-shot prompting" resultera i förbättrad precision? Forskningsresultaten tyder på att det kan göra det, men bara om modellen har ett tillräckligt stort kontextfönster.
Gemini 1.5 Pros större kontextfönster gör att den kan utnyttja fler exempel i kontexten än GPT-modellerna.
Forskarna fann att när man ökar antalet skott från 1 till 800 i reseplaneringen förbättras noggrannheten för Gemini Pro 1.5 från 2,7% till 39,9%.
Tidningen "Dessa resultat visar på möjligheterna med planering i kontext, där LLM:er med hjälp av funktioner för lång kontext kan utnyttja ytterligare kontext för att förbättra planeringen."
Ett märkligt resultat var att GPT-4o var riktigt dålig på reseplanering. Forskarna upptäckte att den hade svårt att "förstå och respektera begränsningar i fråga om flygförbindelser och resedatum".
Ett annat märkligt resultat var att självkorrigering ledde till en betydande minskning av modellens prestanda för alla modeller. När modellerna uppmanades att kontrollera sitt arbete och göra korrigeringar gjorde de fler misstag.
Intressant är att de starkare modellerna, som GPT-4 och Gemini 1.5 Pro, drabbades av större förluster än GPT-3.5 vid självkorrigering.
Agentisk AI är ett spännande perspektiv och vi ser redan några praktiska användningsfall i Microsoft Copilot agenter.
Men resultaten av NATURAL PLANs benchmarkingtester visar att vi har en bit kvar innan AI kan hantera mer komplex planering.
DeepMind-forskarna drog slutsatsen att "NATURAL PLAN är mycket svår för avancerade modeller att lösa".
Det verkar som om AI inte kommer att ersätta resebyråer och personliga assistenter riktigt än.



