

Microsoft lanserade Phi-3 Mini, en liten språkmodell som är en del av företagets strategi att utveckla lätta, funktionsspecifika AI-modeller.
Utvecklingen av språkmodeller har inneburit allt större parametrar, träningsdataset och kontextfönster. Att skala upp storleken på dessa modeller gav kraftfullare funktioner, men till en kostnad.
Det traditionella tillvägagångssättet för att utbilda en LLM är att låta den konsumera stora mängder data, vilket kräver enorma dataresurser. Att utbilda en LLM som GPT-4, till exempel, beräknas ha tagit cirka 3 månader och kostat över $21 miljoner.
GPT-4 är en bra lösning för uppgifter som kräver komplexa resonemang, men överflödig för enklare uppgifter som att skapa innehåll eller en säljchattbot. Det är som att använda en schweizisk armékniv när allt du behöver är en enkel brevöppnare.
Med endast 3,8B parametrar är Phi-3 Mini liten. Ändå säger Microsoft att det är en idealisk lättviktslösning till låg kostnad för uppgifter som att sammanfatta ett dokument, extrahera insikter från rapporter och skriva produktbeskrivningar eller inlägg i sociala medier.
MMLU:s jämförelsesiffror visar att Phi-3 Mini och de större Phi-modellerna som ännu inte släppts slår större modeller som Mistral 7B och Gemma 7B.
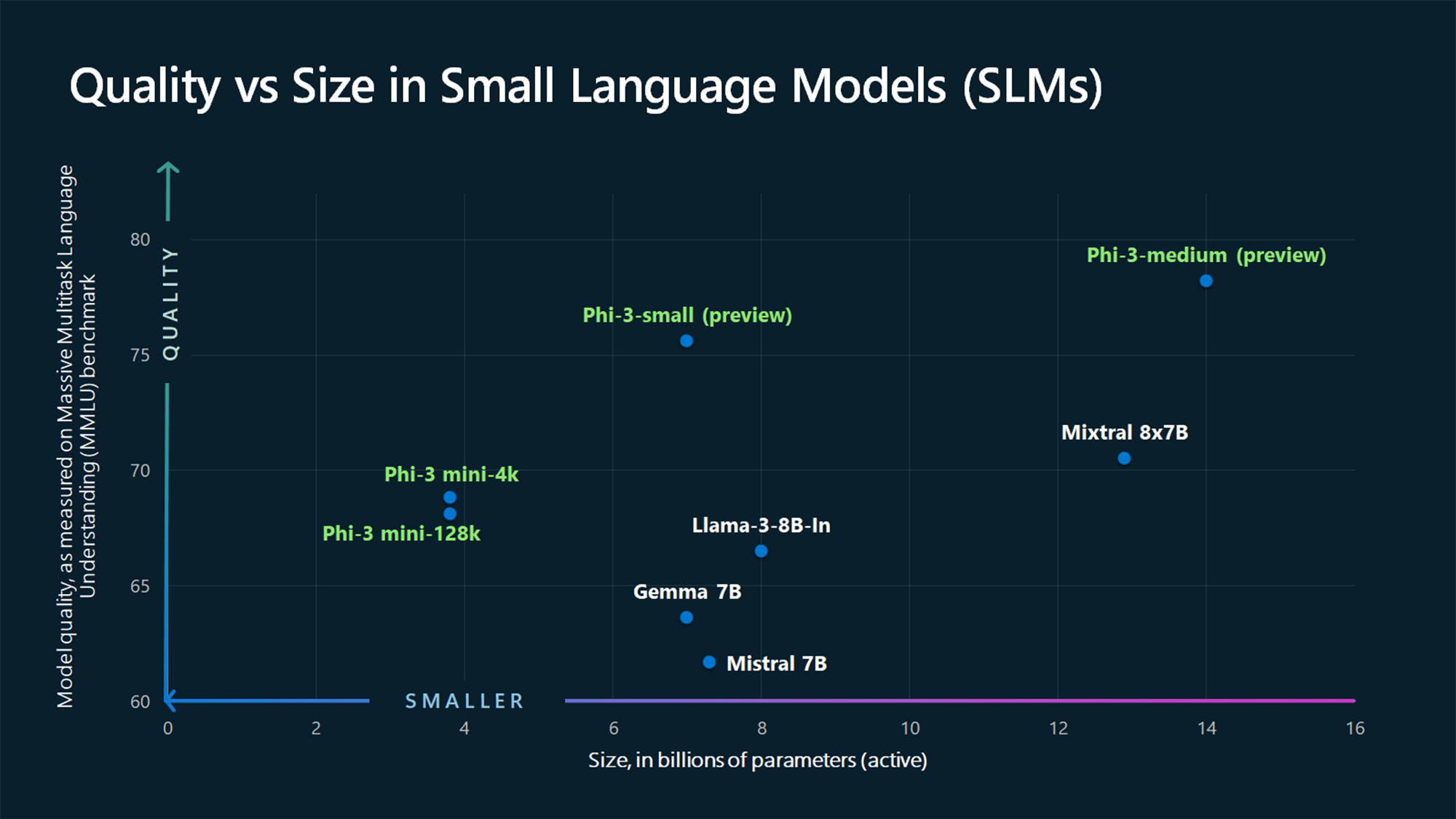
Microsoft säger att Phi-3-small (7B parametrar) och Phi-3-medium (14B parametrar) kommer att finnas tillgängliga i Azure AI Model Catalog "inom kort".
Större modeller som GPT-4 är fortfarande guldstandarden och vi kan nog förvänta oss att GPT-5 blir ännu större.
SLM:er som Phi-3 Mini erbjuder några viktiga fördelar som större modeller inte har. SLM:er är billigare att finjustera, kräver mindre beräkning och kan köras på enheten även i situationer där det inte finns någon internetuppkoppling.
Att distribuera en SLM vid kanten ger mindre latens och maximal sekretess eftersom data inte behöver skickas fram och tillbaka till molnet.
Här är Sebastien Bubeck, VP för GenAI-forskning på Microsoft AI, med en demo av Phi-3 Mini. Den är supersnabb och imponerande för att vara en så liten modell.
phi-3 är här, och det är ... bra :-).
Jag gjorde en snabb kort demo för att ge dig en känsla av vad phi-3-mini (3.8B) kan göra. Håll ögonen öppna för den öppna viktreleasen och fler tillkännagivanden i morgon bitti!
(Och naturligtvis skulle detta inte vara komplett utan den vanliga tabellen med benchmarks!) pic.twitter.com/AWA7Km59rp
- Sebastien Bubeck (@SebastienBubeck) 23 april 2024
Kuraterad syntetisk data
Phi-3 Mini är ett resultat av att man inte längre tror att stora datamängder är det enda sättet att träna en modell.
Sebastien Bubeck, Microsofts vice president för generativ AI-forskning, frågade "Istället för att träna på bara rå webbdata, varför letar du inte efter data som är av extremt hög kvalitet?"
Ronen Eldan, maskininlärningsexpert på Microsoft Research, läste godnattsagor för sin dotter när han undrade om en språkmodell kunde lära sig att använda ord som en 4-åring kunde förstå.
Detta ledde till ett experiment där de skapade ett dataset som började med 3.000 ord. Med hjälp av endast detta begränsade ordförråd fick de en LLM att skapa miljontals korta barnberättelser som sammanställdes i en dataset som heter TinyStories.
Forskarna använde sedan TinyStories för att träna en extremt liten modell med 10 miljoner parametrar som sedan kunde generera "flytande berättelser med perfekt grammatik".
De fortsatte att iterera och skala denna metod för generering av syntetiska data för att skapa mer avancerade, men noggrant kuraterade och filtrerade syntetiska dataset som så småningom användes för att träna Phi-3 Mini.
Resultatet är en liten modell som blir billigare att köra samtidigt som den erbjuder prestanda som är jämförbara med GPT-3.5.
Mindre men mer kapabla modeller gör att företagen kommer att gå ifrån att bara välja stora LLM:er som GPT-4 som standard. Vi kan också snart få se lösningar där en LLM hanterar de tunga lyften men delegerar enklare uppgifter till lättviktsmodeller.



