

Forskare från DeepMind och Stanford University har utvecklat en AI-agent som faktagranskar LLM:er och möjliggör benchmarking av AI-modellers faktamässighet.
Även de bästa AI-modellerna tenderar fortfarande att hallucinera ibland. Om du ber ChatGPT att ge dig fakta om ett ämne, ju längre svaret är desto mer sannolikt är det att det innehåller fakta som inte är sanna.
Vilka modeller är mer faktamässigt korrekta än andra när de genererar längre svar? Det är svårt att säga eftersom vi fram till nu inte har haft något riktmärke som mäter sakligheten i LLM:s långa svar.
DeepMind använde först GPT-4 för att skapa LongFact, en uppsättning med 2 280 uppmaningar i form av frågor relaterade till 38 ämnen. Dessa uppmaningar framkallar långformade svar från den LLM som testas.
De skapade sedan en AI-agent som använde GPT-3.5-turbo för att använda Google för att verifiera hur faktiska svaren som LLM genererade var. De kallade metoden Search-Augmented Factuality Evaluator (SAFE).
SAFE delar först upp det långa svaret från LLM i enskilda fakta. Sedan skickar den sökförfrågningar till Google Search och resonerar om sanningshalten i fakta baserat på information i de returnerade sökresultaten.
Här är ett exempel från forskningsrapport.
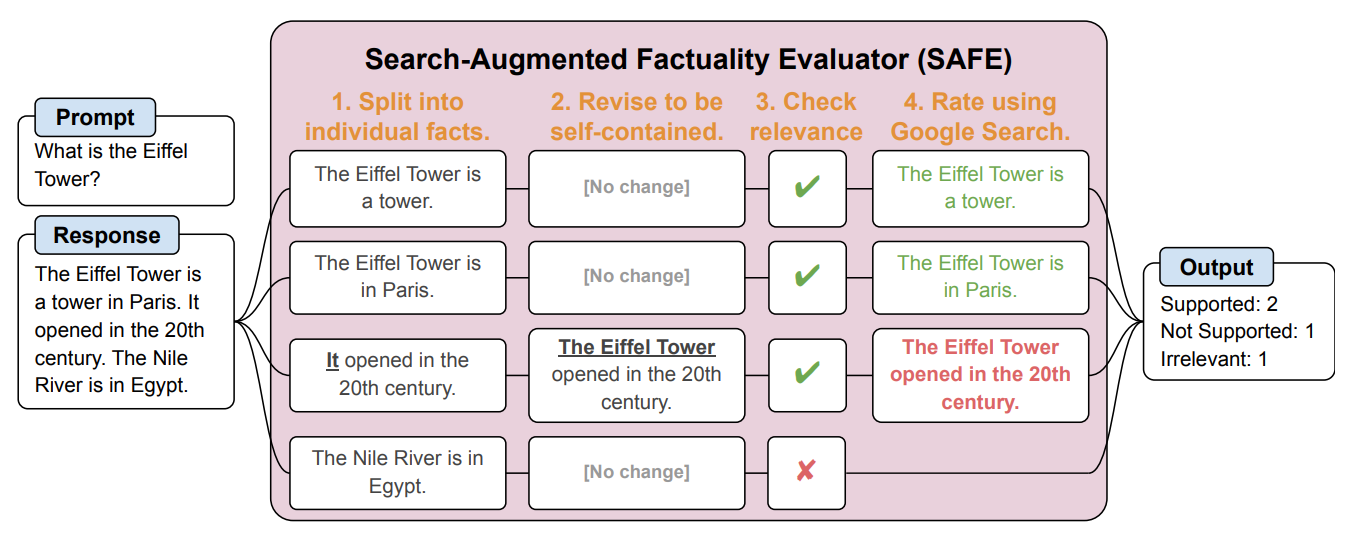
Forskarna säger att SAFE uppnår "övermänskliga prestanda" jämfört med mänskliga kommentatorer som gör faktakontrollen.
SAFE instämde med 72% av de mänskliga annotationerna, och när det skilde sig från de mänskliga annotationerna visade det sig att SAFE hade rätt 76% av gångerna. Det var också 20 gånger billigare än mänskliga annotatorer från crowdsourcing. LLM:er är alltså bättre och billigare faktakontrollanter än vad människor är.
Kvaliteten på svaret från de testade LLM-läkarna mättes utifrån antalet faktoider i svaret i kombination med hur faktabaserade de enskilda faktoiderna var.
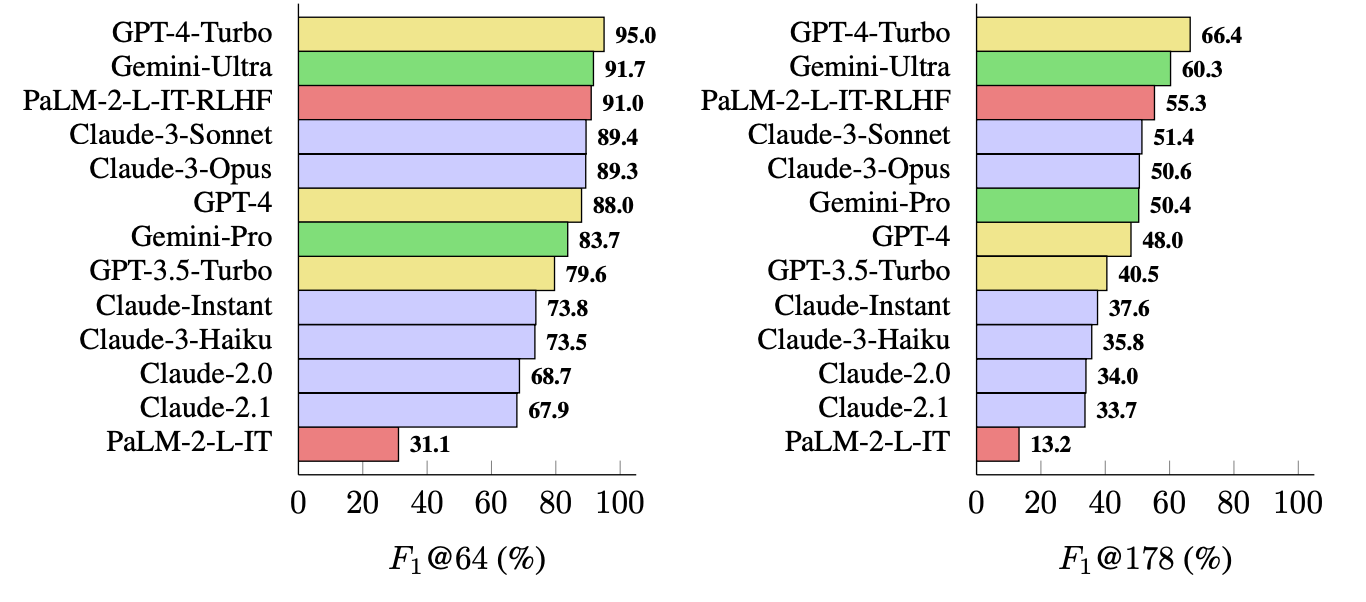
Det mått som de använde (F1@K) uppskattar det "ideala" antalet fakta i ett svar som människan föredrar. I benchmarktesterna användes 64 som median för K och 178 som maximum.
Enkelt uttryckt är F1@K ett mått på "Gav svaret mig så mycket fakta som jag ville ha?" i kombination med "Hur många av dessa fakta var sanna?".
Vilken LLM är mest saklig?
Forskarna använde LongFact för att fråga 13 LLM:er från familjerna Gemini, GPT, Claude och PaLM-2. Sedan använde de SAFE för att utvärdera hur faktabaserade deras svar var.
GPT-4-Turbo toppar listan som den mest faktabaserade modellen när det gäller att generera långa svar. Den följdes tätt av Gemini-Ultra och PaLM-2-L-IT-RLHF. Resultaten visade att större LLM:er är mer faktabaserade än mindre.
F1@K-beräkningen skulle förmodligen få datavetare att häpna, men för enkelhetens skull visar dessa benchmarkresultat hur faktabaserad varje modell är när den returnerar medellånga och längre svar på frågorna.
SAFE är ett billigt och effektivt sätt att kvantifiera LLM-faktualitet i lång form. Det är snabbare och billigare än människor när det gäller faktakontroll, men det beror fortfarande på sanningshalten i den information som Google returnerar i sökresultaten.
DeepMind släppte SAFE för allmän användning och föreslog att det skulle kunna hjälpa till att förbättra LLM-faktualiteten genom bättre förträning och finjustering. Det skulle också kunna göra det möjligt för en LLM att kontrollera sina fakta innan den presenterar resultatet för en användare.
OpenAI kommer att bli glada över att se att forskning från Google visar att GPT-4 slår Gemini i ännu ett benchmark.



