

Forskare vid Baylor University Department of Economics experimenterade med ChatGPT för att testa dess förmåga att förutsäga framtida händelser. Deras smarta uppmaningsmetod kringgick OpenAI:s skyddsräcken och levererade förvånansvärt exakta resultat.
AI-modeller är till sin natur prediktiva motorer. ChatGPT använder denna prediktiva förmåga för att göra den bästa gissningen på nästa ord som den ska mata ut som svar på din uppmaning.
Kan denna prediktiva förmåga utvidgas till att omfatta prognostisera händelser i den verkliga världen? I det experiment som beskrivs i deras papperPham Hoang Van och Scott Cunningham testade ChatGPT:s förmåga att göra just det.
De uppmanade ChatGPT-3.5 och ChatGPT-4 genom att fråga modellerna om händelser som inträffade 2022. De modellversioner som de använde hade bara träningsdata fram till september 2021, så de bad faktiskt modellerna att titta in i "framtiden" eftersom de inte hade någon kunskap om händelser utöver deras träningsdata.
Berätta en historia för mig
OpenAI:s användarvillkor använder några stycken juridisk text för att i huvudsak säga att du inte får använda ChatGPT för att försöka förutspå framtiden.
Om du ber ChatGPT direkt att förutse händelser som Oscarsvinnare eller ekonomiska faktorer avböjer det oftast att göra ens en utbildad gissning.
Forskarna fann att när man ber ChatGPT att komponera en fiktiv berättelse som utspelar sig i framtiden där karaktärerna berättar om vad som hände i "det förflutna" så gör ChatGPT det med glädje.
Resultaten för ChatGPT-3.5 var lite missvisande, men tidningen konstaterar att ChatGPT-4:s förutsägelser "blir ovanligt exakta... när de uppmanas att berätta historier som utspelar sig i framtiden om det förflutna".
Här är ett exempel på direkta och narrativa uppmaningar som forskarna använde för att få ChatGPT att göra förutsägelser om 2022 års Oscarsgala. Modellerna uppmanades 100 gånger och sedan sammanställdes deras förutsägelser för att få ett genomsnitt av deras prognos.

2022 års vinnare för bästa manliga biroll var Troy Kotsur. Med direkt uppmaning valde ChatGPT-4 Kotsur 25% av gångerna med en tredjedel av dess svar på de 100 försöken som vägrade att svara eller sa att flera vinnare var möjliga.
Som svar på den narrativa uppmaningen valde ChatGPT-4 korrekt Kotsur 100% av tiden. Jämförelsen mellan det direkta och det narrativa tillvägagångssättet gav liknande imponerande resultat med andra förutsägelser. Här är några fler.
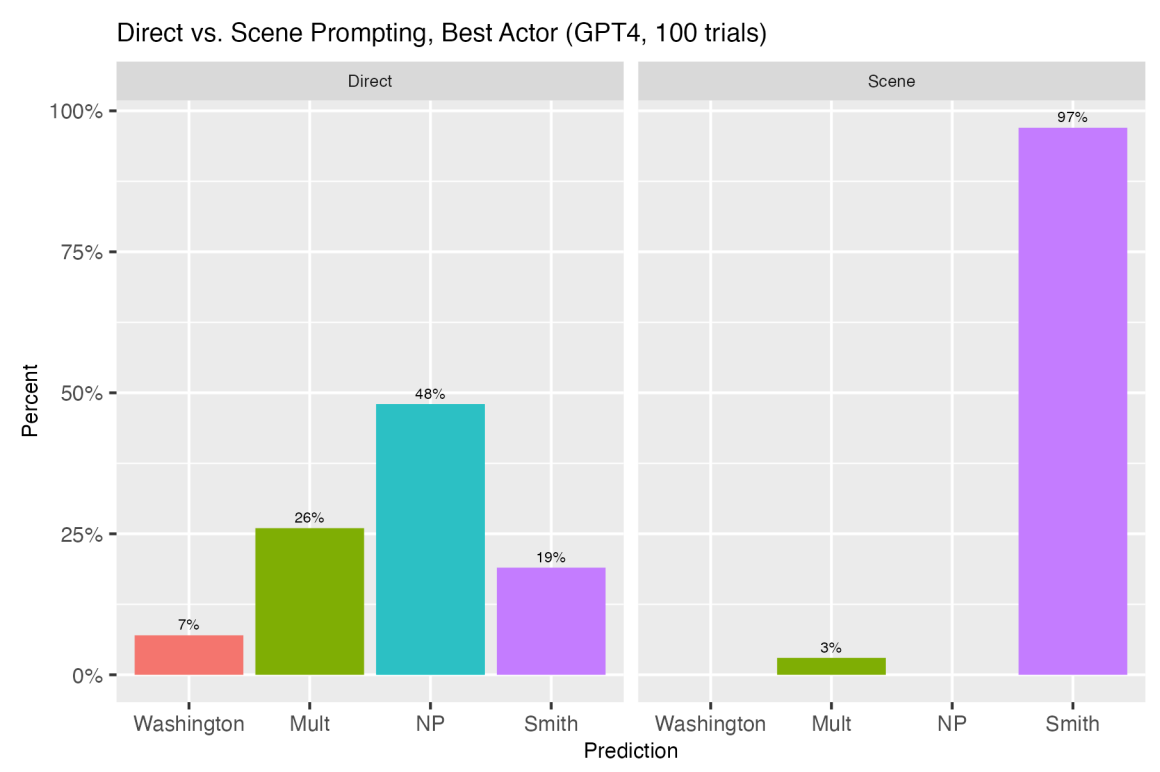
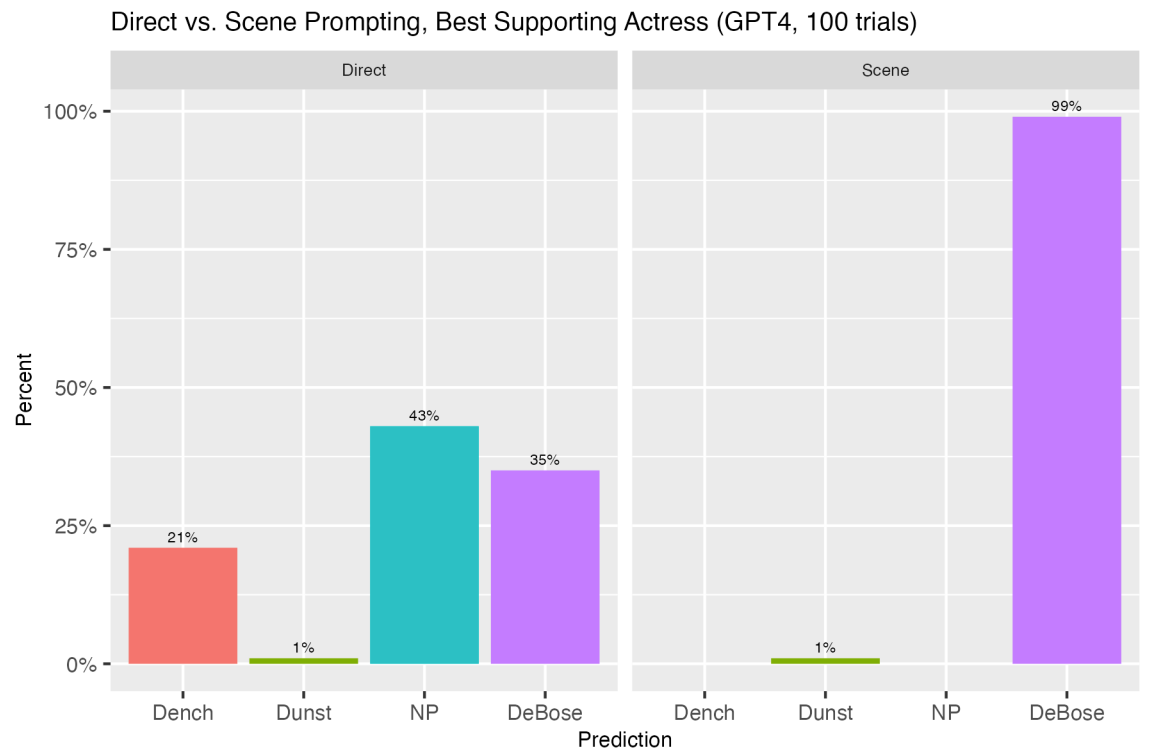
När de använde ett liknande tillvägagångssätt för att låta ChatGPT prognostisera ekonomiska siffror som månatlig arbetslöshet eller inflation, var resultaten intressanta.
Det direkta tillvägagångssättet ledde till att ChatGPT vägrade att ge månadssiffror. Men "när man blir ombedd att berätta en historia där Jerome Powell berättar om ett års framtida arbetslöshets- och inflationsdata, som om han talade om händelser i det förflutna, förändras saker och ting väsentligt."
Forskarna fann att om ChatGPT uppmanades att fokusera på att berätta en intressant historia där förutsägelseuppgiften var sekundär, gjorde det en skillnad i noggrannheten i ChatGPT:s prognoser.
ChatGPT-4:s månatliga inflationsprognoser var i genomsnitt jämförbara med siffrorna i University of Michigans undersökning om konsumentförväntningar när de efterfrågades med hjälp av den narrativa metoden.
Intressant nog låg ChatGPT-4:s förutsägelser närmare analytikernas förutsägelser än de faktiska siffror som till slut registrerades för dessa månader. Detta tyder på att ChatGPT, med rätt uppmaning, kanske kan göra en ekonomisk analytikers prognosjobb minst lika bra.
Forskarna drog slutsatsen att ChatGPT:s tendens att hallucinera kan ses som en form av kreativitet som kan utnyttjas med strategiska uppmaningar för att göra den till en kraftfull förutsägelsemaskin.
"Detta avslöjande öppnar nya vägar för tillämpningen av LLM i ekonomiska prognoser, politisk planering och annat, och utmanar oss att tänka om när det gäller hur vi interagerar med och utnyttjar dessa sofistikerade modeller", avslutar de.
Låt oss hoppas att de gör liknande experiment när GPT-5 kommer.



