

Apples ingenjörer har utvecklat ett AI-system som löser komplexa referenser till enheter på skärmen och användarkonversationer. Den lätta modellen skulle kunna vara en idealisk lösning för virtuella assistenter på enheter.
Människor är bra på att lösa referenser i konversationer med varandra. När vi använder termer som "den understa" eller "han" förstår vi vad personen syftar på utifrån konversationens sammanhang och saker vi kan se.
Det är mycket svårare för en AI-modell att göra detta. Multimodala LLM:er som GPT-4 är bra på att svara på frågor om bilder, men de är dyra att träna och kräver mycket datorkostnader för att bearbeta varje fråga om en bild.
Apples ingenjörer använde ett annat tillvägagångssätt med sitt system, som kallas ReALM (Reference Resolution As Language Modeling). Tidningen är värt att läsa för mer information om deras utvecklings- och testprocess.
ReALM använder en LLM för att bearbeta samtals-, skärm- och bakgrundsenheter (larm, bakgrundsmusik) som utgör en användares interaktion med en virtuell AI-agent.
Här är ett exempel på den typ av interaktion som en användare kan ha med en AI-agent.
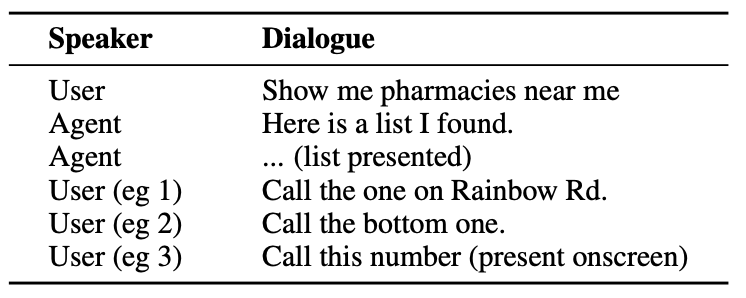
Agenten måste förstå konversationsenheter som att när användaren säger "den där" syftar han eller hon på telefonnumret till apoteket.
Den måste också förstå det visuella sammanhanget när användaren säger "den nedersta", och det är här ReALM:s metod skiljer sig från modeller som GPT-4.
ReALM förlitar sig på uppströms kodare för att först analysera elementen på skärmen och deras positioner. ReALM rekonstruerar sedan skärmen i rent textuella representationer från vänster till höger och uppifrån och ned.
Enkelt uttryckt används naturligt språk för att sammanfatta användarens skärm.
När en användare nu ställer en fråga om något på skärmen bearbetar språkmodellen textbeskrivningen av skärmen i stället för att behöva använda en synmodell för att bearbeta bilden på skärmen.
Forskarna skapade syntetiska dataset med enheter i samtal, på skärmen och i bakgrunden och testade ReALM och andra modeller för att se hur effektiva de är när det gäller att lösa referenser i samtalssystem.
ReALM:s mindre version (80M parametrar) presterade jämförbart med GPT-4 och dess större version (3B parametrar) presterade betydligt bättre än GPT-4.
ReALM är en liten modell jämfört med GPT-4. Dess överlägsna referensupplösning gör den till ett perfekt val för en virtuell assistent som kan finnas på enheten utan att kompromissa med prestandan.
ReALM fungerar inte lika bra med mer komplexa bilder eller nyanserade användarförfrågningar, men det skulle kunna fungera bra som en virtuell assistent i en bil eller på en enhet. Tänk om Siri kunde "se" din iPhone-skärm och svara på hänvisningar till element på skärmen.
Apple har varit lite långsamma i starten, men den senaste tidens utveckling, som MM1-modell och ReALM visar att det händer mycket bakom stängda dörrar.



