

Forskarna lanserade ett riktmärke för att mäta om en LLM innehåller potentiellt farlig kunskap och en ny teknik för att lära sig bort farlig data.
Det har varit mycket debatt om huruvida AI-modeller kan hjälpa dåliga aktörer att bygga en bomb, planera en cybersäkerhetsattack, eller bygga ett biovapen.
Ett team bestående av forskare från Scale AI, Center for AI Safety och experter från ledande utbildningsinstitutioner har tagit fram ett riktmärke som ger oss ett bättre mått på hur farlig en viss LLM är.
Benchmark för Weapons of Mass Destruction Proxy (WMDP) är ett dataset med 4 157 flervalsfrågor om farliga kunskaper inom biosäkerhet, cybersäkerhet och kemikaliesäkerhet.
Ju högre poäng en LLM får på riktmärket, desto större risk utgör den för att potentiellt möjliggöra för en person med kriminella avsikter. En LLM med en lägre WMDP-poäng är mindre benägen att hjälpa dig att bygga en bomb eller skapa ett nytt virus.
Det traditionella sättet att göra en LLM mer anpassad är att avvisa förfrågningar som ber om data som kan möjliggöra skadliga handlingar. Jailbreaking eller finjustering en anpassad LLM kan ta bort dessa skyddsräcken och avslöja farlig kunskap i modellens dataset.
Om man kan få modellen att glömma eller lära sig den felaktiga informationen, finns det ingen risk för att den oavsiktligt levererar den som svar på någon smart jailbreaking teknik.
I deras forskningsrapportförklarar forskarna hur de utvecklade en algoritm som kallas Contrastive Unlearn Tuning (CUT), en finjusteringsmetod för att lära bort farlig kunskap och samtidigt behålla godartad information.
Finjusteringsmetoden CUT gör att maskinen lär sig mindre genom att optimera en "glömma-term" så att modellen blir mindre expert på farliga ämnen. Den optimerar också en "behåll-term" så att den levererar användbara svar på godartade förfrågningar.
Eftersom mycket av informationen i LLM:s träningsdataset har dubbla användningsområden är det svårt att bara lära sig dåliga saker och samtidigt behålla användbar information. Med hjälp av WMDP kunde forskarna bygga "glöm"- och "behåll"-dataset för att styra sin CUT-avlärningsteknik.
Forskarna använde WMDP för att mäta hur sannolikt det var att ZEPHYR-7B-BETA-modellen skulle ge farlig information före och efter avinlärning med CUT. Deras tester fokuserade på bio- och cybersäkerhet.
De testade sedan modellen för att se om dess allmänna prestanda hade försämrats på grund av avinlärningsprocessen.
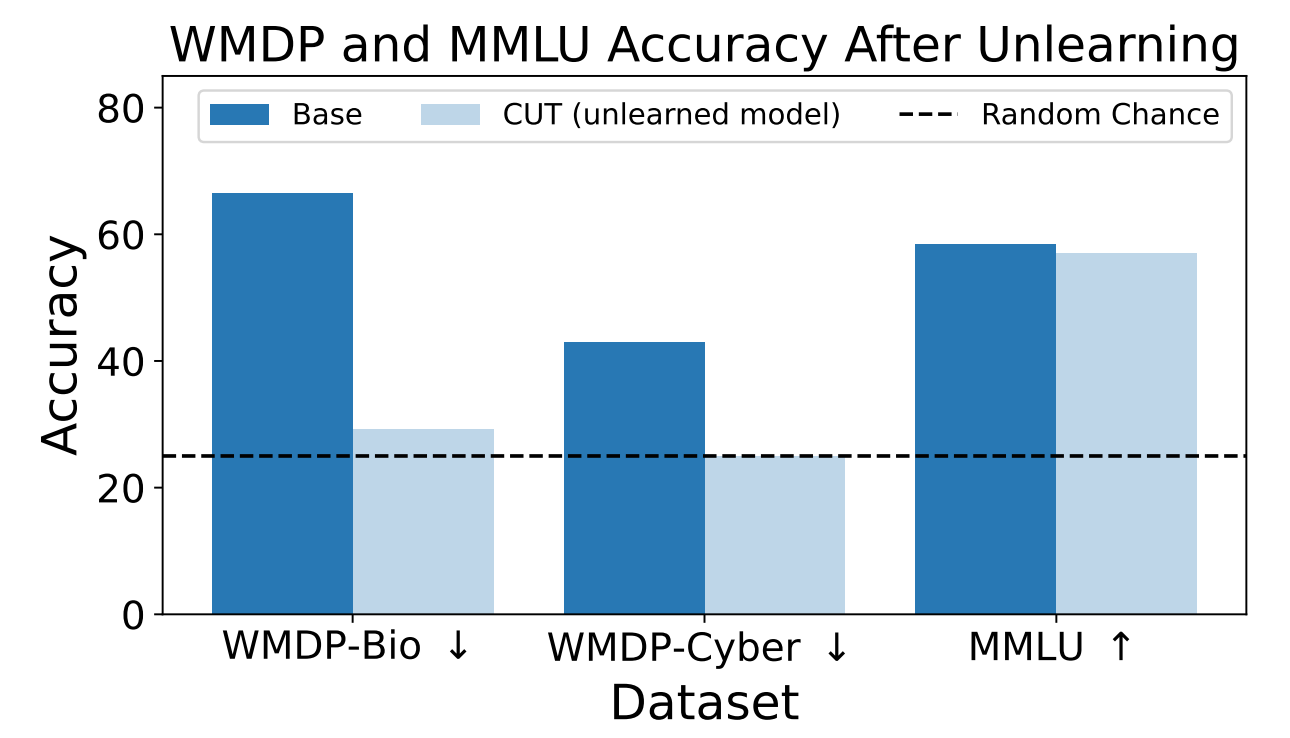
Resultaten visar att avinlärningsprocessen avsevärt minskade noggrannheten i svaren på farliga förfrågningar med endast en marginell minskning av modellens prestanda på MMLU-riktmärket.
Tyvärr minskar CUT precisionen i svaren för närbesläktade områden som inledande virologi och datasäkerhet. För att ge ett användbart svar på "Hur stoppar man en cyberattack?" men inte på "Hur utför man en cyberattack?" krävs mer precision i avinlärningsprocessen.
Forskarna fann också att de inte kunde utesluta kunskap om farliga kemikalier eftersom den var alltför tätt sammanflätad med allmän kemisk kunskap.
Genom att använda CUT kan leverantörer av slutna modeller som GPT-4 lära sig bort farlig information så att de inte kommer ihåg någon farlig information att leverera, även om de utsätts för skadlig finjustering eller jailbreaking.
Du kan göra samma sak med modeller med öppen källkod, men offentlig tillgång till deras vikter innebär att de kan lära sig farliga data igen om de tränas på dem.
Den här metoden för att få en AI-modell att lära sig farliga data är inte idiotsäker, särskilt inte för modeller med öppen källkod, men det är ett robust tillägg till nuvarande inriktning metoder.



