

Apple har ännu inte officiellt lanserat någon AI-modell, men ett nytt forskningsdokument ger en inblick i företagets framsteg när det gäller att utveckla modeller med avancerade multimodala funktioner.
Tidningenmed titeln "MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training", introducerar Apples familj av MLLMs som kallas MM1.
MM1 uppvisar imponerande förmågor inom bildtextning, visuellt frågesvar (VQA) och inferens av naturligt språk. Forskarna förklarar att noggranna val av bildtextpar gjorde det möjligt för dem att uppnå överlägsna resultat, särskilt i inlärningsscenarier med få bilder.
Det som skiljer MM1 från andra MLLM är dess överlägsna förmåga att följa instruktioner över flera bilder och att resonera kring de komplexa scener som den presenteras för.
MM1-modellerna innehåller upp till 30B parametrar, vilket är tre gånger så mycket som GPT-4V, den komponent som ger OpenAI:s GPT-4 dess visionskapacitet.
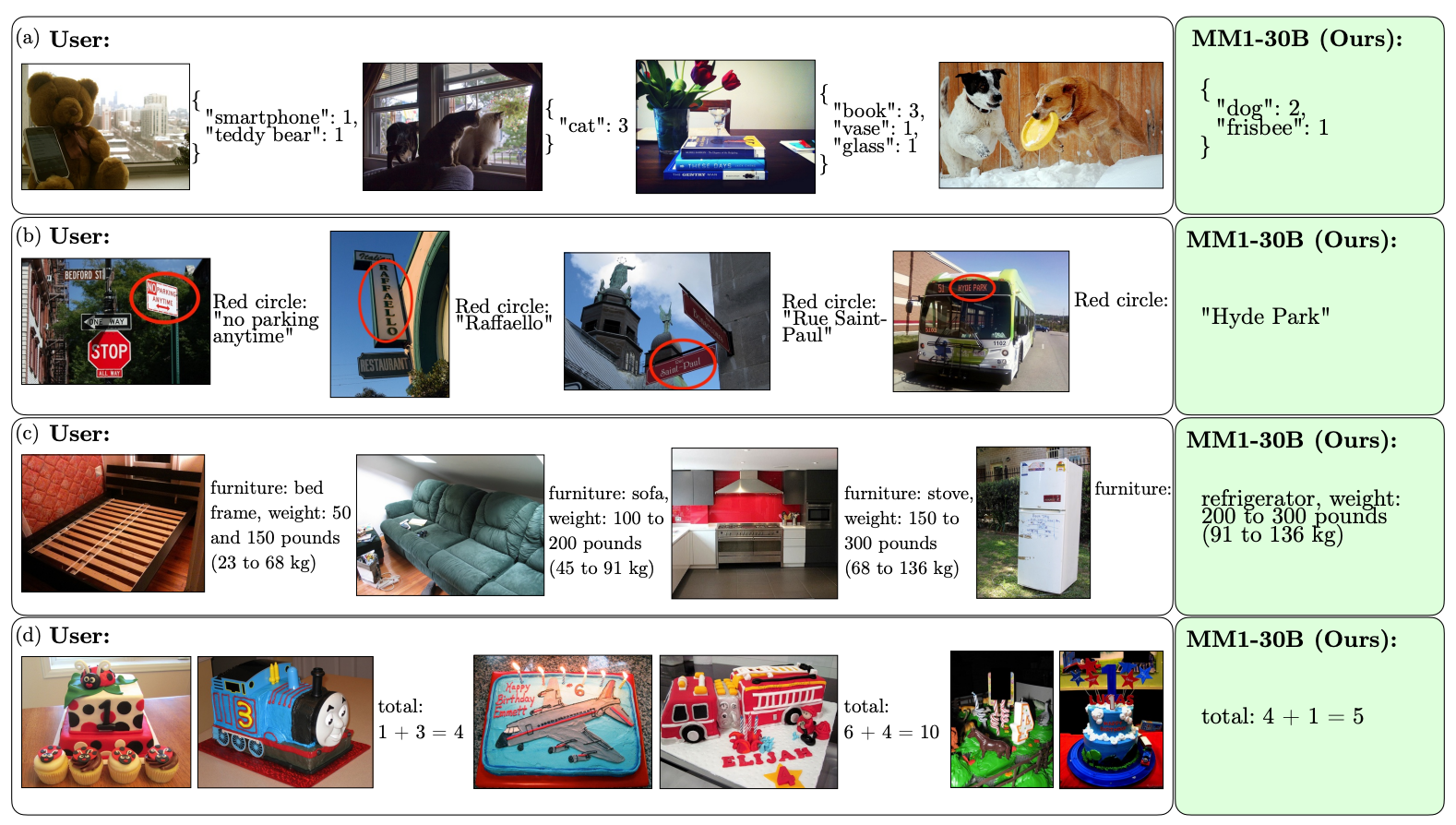
Här är några exempel på MM1:s VQA-förmåga.

MM1 genomgick storskalig multimodal förträning på "en dataset med 500M sammanflätade bild-textdokument, som innehåller 1B bilder och 500B texttokens".
Omfattningen och mångfalden av dess förträning gör att MM1 kan utföra imponerande förutsägelser i kontext och följa anpassad formatering med ett litet antal exempel med få bilder. Här är exempel på hur MM1 lär sig önskad utdata och format från bara 3 exempel.
För att skapa AI-modeller som kan "se" och resonera krävs en "vision-language connector" som översätter bilder och språk till en enhetlig representation som modellen kan använda för vidare bearbetning.
Forskarna fann att utformningen av vision-language-kontakten hade mindre betydelse för MM1:s prestanda. Intressant nog var det bildupplösningen och antalet bildtokens som hade störst inverkan.
Det är intressant att se hur öppna Apple har varit när det gäller att dela med sig av sin forskning till det bredare AI-samhället. Forskarna säger att "i det här dokumentet dokumenterar vi MLLM-byggnadsprocessen och försöker formulera designlektioner som vi hoppas kan vara till nytta för samhället."
De publicerade resultaten kommer sannolikt att påverka vilken riktning andra MMLM-utvecklare tar när det gäller arkitektur och val av data för förträning.
Exakt hur MM1-modellerna kommer att implementeras i Apples produkter återstår att se. De publicerade exemplen på MM1:s kapacitet antyder att Siri kommer att bli mycket smartare när hon så småningom lär sig att se.



