

Forskare från UC San Diego och New York University har utvecklat V*, en LLM-styrd sökalgoritm som är mycket bättre än GPT-4V på kontextuell förståelse och exakt inriktning på specifika visuella element i bilder.
Multimodala stora språkmodeller (MLLM) som OpenAI:s GPT-4V slog oss med häpnad förra året med sin förmåga att svara på frågor om bilder. Hur imponerande GPT-4V än är så kämpar den ibland när bilderna är mycket komplexa och missar ofta små detaljer.
V*-algoritmen använder en Visual Question Answering (VQA) LLM för att identifiera vilket område i bilden den ska fokusera på för att besvara en visuell fråga. Forskarna kallar denna kombination för Show, sEArch och telL (SEAL).
Om någon gav dig en högupplöst bild och ställde en fråga om den, skulle din logik leda dig till att zooma in på ett område där det är mest sannolikt att du hittar föremålet i fråga. SEAL använder V* för att analysera bilder på ett liknande sätt.
En visuell sökmodell skulle helt enkelt kunna dela upp en bild i block, zooma in i varje block och sedan bearbeta den för att hitta objektet i fråga, men det är beräkningsmässigt mycket ineffektivt.
När V* får en textuell fråga om en bild försöker den först lokalisera bildmålet direkt. Om det inte går ber den MLLM att använda sunt förnuft för att identifiera vilket område i bilden som det är mest troligt att målet befinner sig i.
Den fokuserar sedan sin sökning på just det området, i stället för att försöka göra en "inzoomad" sökning av hela bilden.

När GPT-4V uppmanas att svara på frågor om en bild som kräver omfattande visuell bearbetning av högupplösta bilder är det svårt. SEAL som använder V* presterar mycket bättre.

På frågan "Vilken typ av dryck kan vi köpa från den där automaten?" svarade SEAL "Coca-Cola" medan GPT-4V felaktigt gissade på "Pepsi".
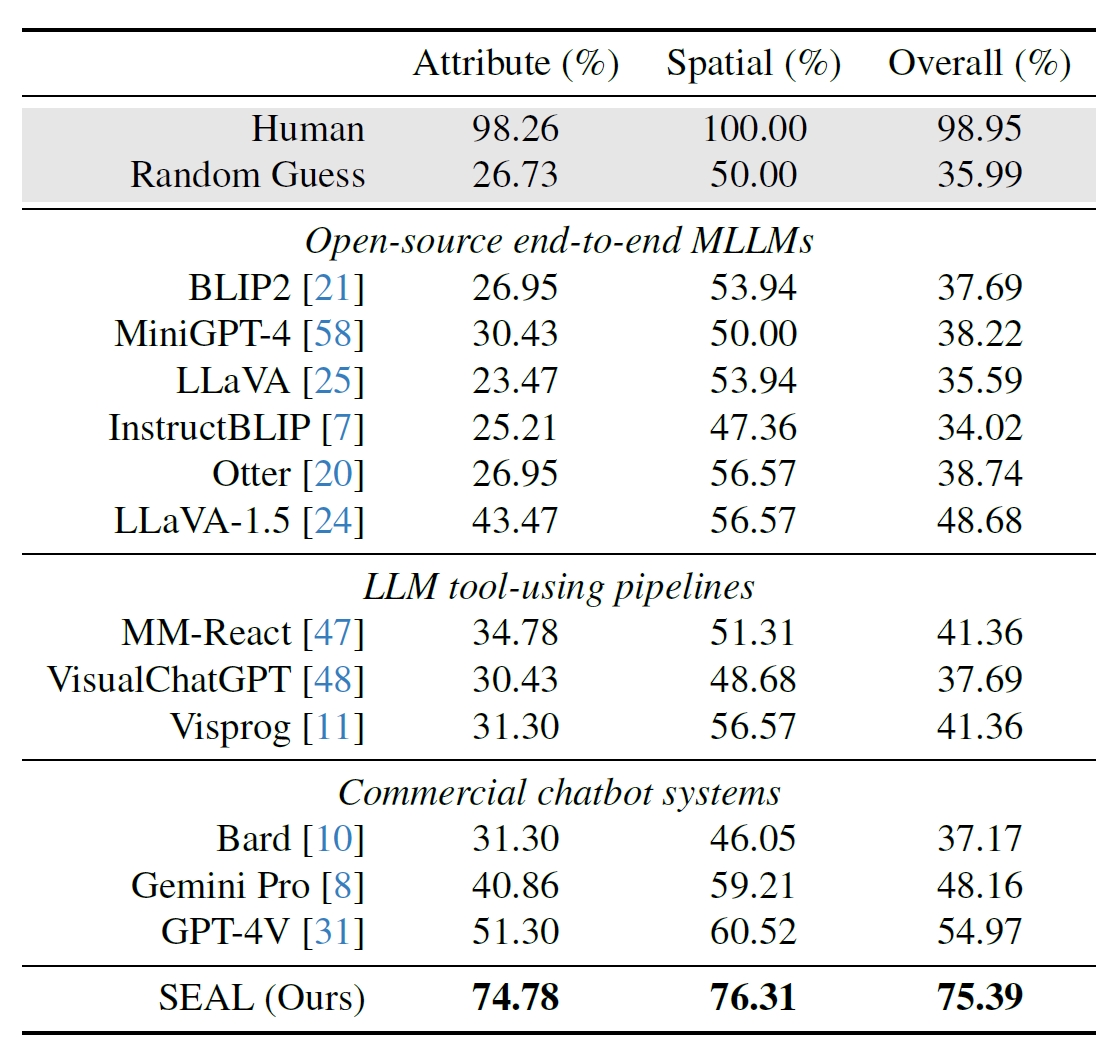
Forskarna använde 191 högupplösta bilder från Meta's Segment Anything (SAM) dataset och skapade ett riktmärke för att se hur SEALs prestanda jämfördes med andra modeller. V*Bench-riktmärket testar två uppgifter: attributigenkänning och resonemang om rumsliga relationer.
Figurerna nedan visar mänsklig prestanda jämfört med modeller med öppen källkod, kommersiella modeller som GPT-4V och SEAL. Den ökning som V* ger i SEAL:s prestanda är särskilt imponerande eftersom den underliggande MLLM som används är LLaVa-7b, som är mycket mindre än GPT-4V.
Denna intuitiva metod för att analysera bilder verkar fungera riktigt bra med ett antal imponerande exempel på sammanfattning på GitHub.
Det ska bli intressant att se om andra MLLM:er, som de från OpenAI eller Google, använder sig av ett liknande tillvägagångssätt.
På frågan om vilken dryck som såldes från automaten på bilden ovan svarade Googles Bard: "Det finns ingen automat i förgrunden." Kanske Gemini Ultra kommer att göra ett bättre jobb.
För närvarande ser det ut som om SEAL och dess nya V*-algoritm ligger en bra bit före några av de största multimodala modellerna när det gäller visuella frågor.



