

Mistral AI är ett franskt AI-startup som skapar rubriker med sina lättviktiga modeller med öppen källkod. Tillsammans med uppmärksamheten kom en ny finansieringssatsning när den säkrade investeringar på 385 miljoner euro, eller $414 miljoner, den här veckan.
Bolagets andra finansieringsrunda leddes av riskkapitalbolagen Andreessen Horowitz och Lightspeed Venture Partners.
Diskussionen om modeller med öppen källkod kontra proprietära modeller pågår ständigt och Mistral AI står fast på den öppna källkodssidan.
Företag som OpenAI har varit kritiserade för sin skrämselpropaganda om säkerheten i modeller med öppen källkod, och många menar att det handlar om att Big Tech försöker behålla sin hegemoni.
Mistral AI säger att genom att träna sina egna modeller "släppa dem öppet och främja bidrag från samhället kan vi bygga ett trovärdigt alternativ till det framväxande AI-oligopolet. Generativa modeller med öppen vikt kommer att spela en central roll i den kommande AI-revolutionen."
Flera stora investerare bekräftade sitt förtroende för denna strategi. Den finansiering Mistral AI säkrade i veckan har företaget värderat till $2 miljarder. Det är en 7-faldig ökning av värderingen under de sex månader som gått sedan företaget lanserades.
Mixtral 8x7B
I september släpptes Mistral 7B, Mistral AI:s lilla men kraftfulla LLM som slog eller matchade större modeller med öppen källkod som Meta's Llama 2 34B.
OpenAI:s egenutvecklade GPT-modeller anses med rätta vara guldstandarden när man jämför modellprestanda. Med Mistral AI:s nya modell, Mixtral 8x7Bhar företaget säkrat betydande rättigheter i detta avseende.
Mixtral 8x7B är en gles Blandning-av-experter modell med ett 32k kontextfönster. Här är hur den presterade i benchmarktester jämfört med Llama 2 och GPT-3.5.
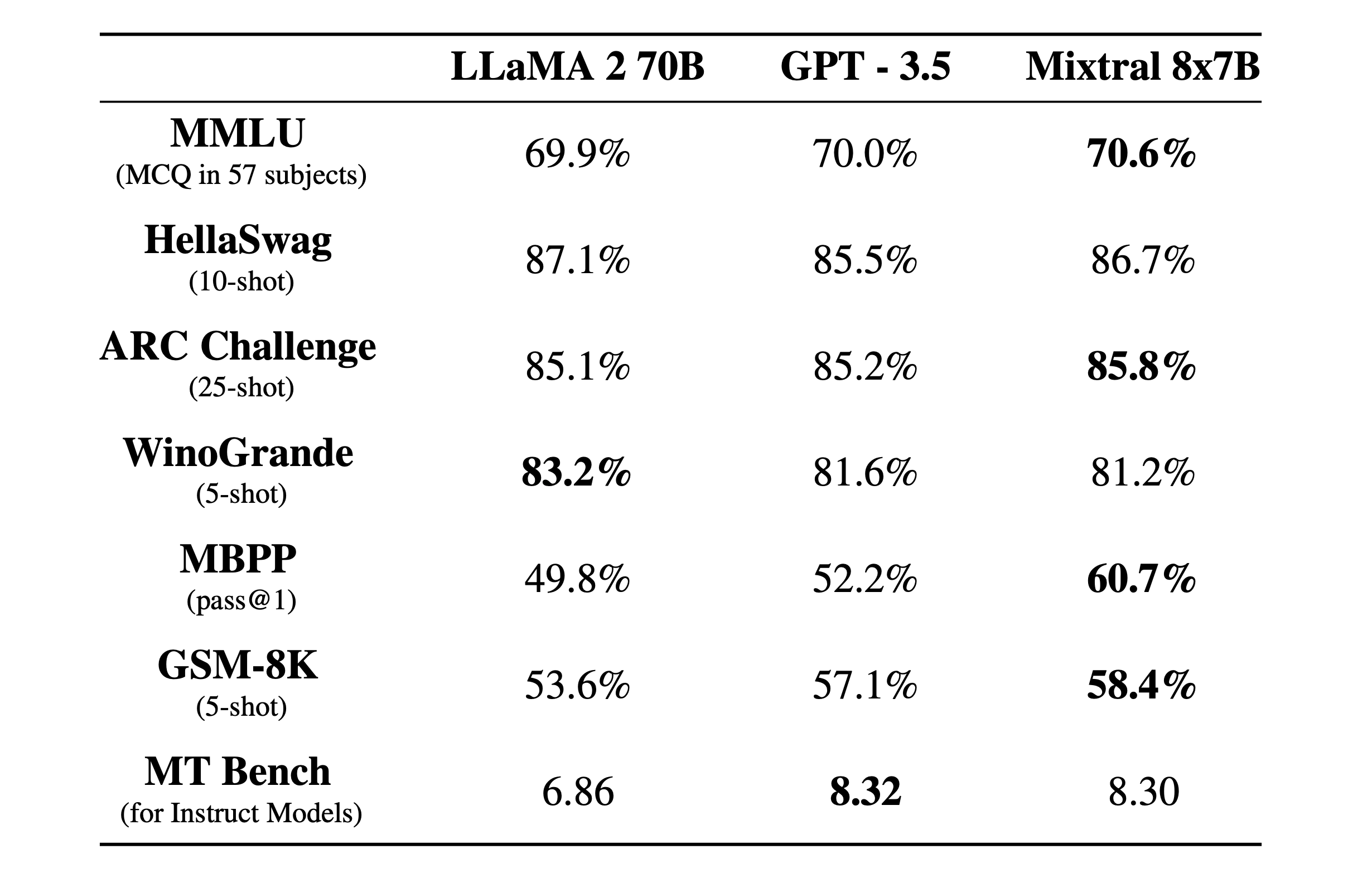
Benchmarktesterna är ett bra sätt att få en uppfattning om hur bra en modell är på att utföra olika funktioner. Testerna ovan var:
- MMLU (MCQ i 57 ämnen): Står för flervalsfrågor i 57 ämnen.
- HellaSwag (10-skott): Utvärderar AI:ns förmåga att förutse slutet på ett scenario efter att ha fått 10 exempel.
- ARC-utmaning (25 skott): Testar AI:ns förståelse för vetenskapliga begrepp och resonemang efter att ha fått 25 exempel att lära sig av innan den testas.
- WinoGrande (5 skott): Testar resonemang med sunt förnuft baserat på att lösa tvetydigheter i meningar, med 5 exempel som AI:n kan lära sig av.
- MBPP (godkänd@1): Testar en AI-modells förmåga att generera korrekta Python-kodsnuttar. Måttet pass@1 mäter procentandelen problem där modellens första avslutning var korrekt.
- GSM-8K (5 bilder): Benchmarket Grade School Math 8K testar en AI:s förmåga att lösa matematiska ordproblem på den nivå som förväntas i grundskolan efter att ha fått 5 exempel.
- MT Bench (för instruktionsmodeller): Machine Translation Benchmark for Instruct Models mäter hur väl en AI kan följa instruktioner i samband med översättningsuppgifter.
Det som är ännu mer imponerande än resultaten från benchmarktesterna är hur liten och effektiv Mixtral 8x7B är. Du kan köra den här modellen lokalt på en hyfsad bärbar dator med cirka 32 GB RAM.
Med mycket mer pengar till sitt förfogande kan vi förvänta oss en del spännande utveckling från Mistral AI.



