

Tidigare den här månaden kunde Google stolt meddela att deras mest kraftfulla Gemini-modell slog GPT-4 i Massive Multitask Language Understanding MMLU benchmark-test. Microsofts nya prompting-teknik gör att GPT-4 återtar förstaplatsen, om än med en bråkdel av en procent.
Förutom dramatiken kring marknadsföringsvideon är Googles Gemini en stor sak för företaget och dess MMLU-benchmarkresultat är imponerande. Men Microsoft, OpenAI:s största investerare, väntade inte länge med att kasta skugga över Googles ansträngningar.
Rubriken är att Microsoft fick GPT-4 att slå Gemini Ultras MMLU-resultat. Verkligheten är att det slog Geminis resultat på 90,04% med bara 0,06%.
Bakgrundshistorien om vad som gjorde detta möjligt är mer spännande än det inkrementella överlägsenhet som vi ser på dessa topplistor. Microsofts nya prompttekniker kan öka prestandan hos äldre AI-modeller.
Kommer du ihåg hur Googles outgivna Gemini Ultra just slog ut GPT-4 för att bli den bästa AI?
Microsoft har just visat att GPT-4, med rätt uppmaning, faktiskt slår Gemini i benchmarks.
Det finns gott om utrymme för förbättringar även med äldre modeller. https://t.co/YQ5zJI6Gad pic.twitter.com/X3HFmXa30X
- Ethan Mollick (@emollick) 12 december 2023
Medprompt
När man talar om att "styra" en modell menar man bara att man med försiktiga uppmaningar kan styra en modell så att den ger ett resultat som är bättre anpassat till det man ville ha.
Microsoft utvecklade en kombination av prompttekniker som visade sig vara riktigt bra på detta. Medprompt startade som ett projekt för att få GPT-4 att ge bättre svar på medicinska utmaningsriktmärken som MultiMedQA-testsviten.
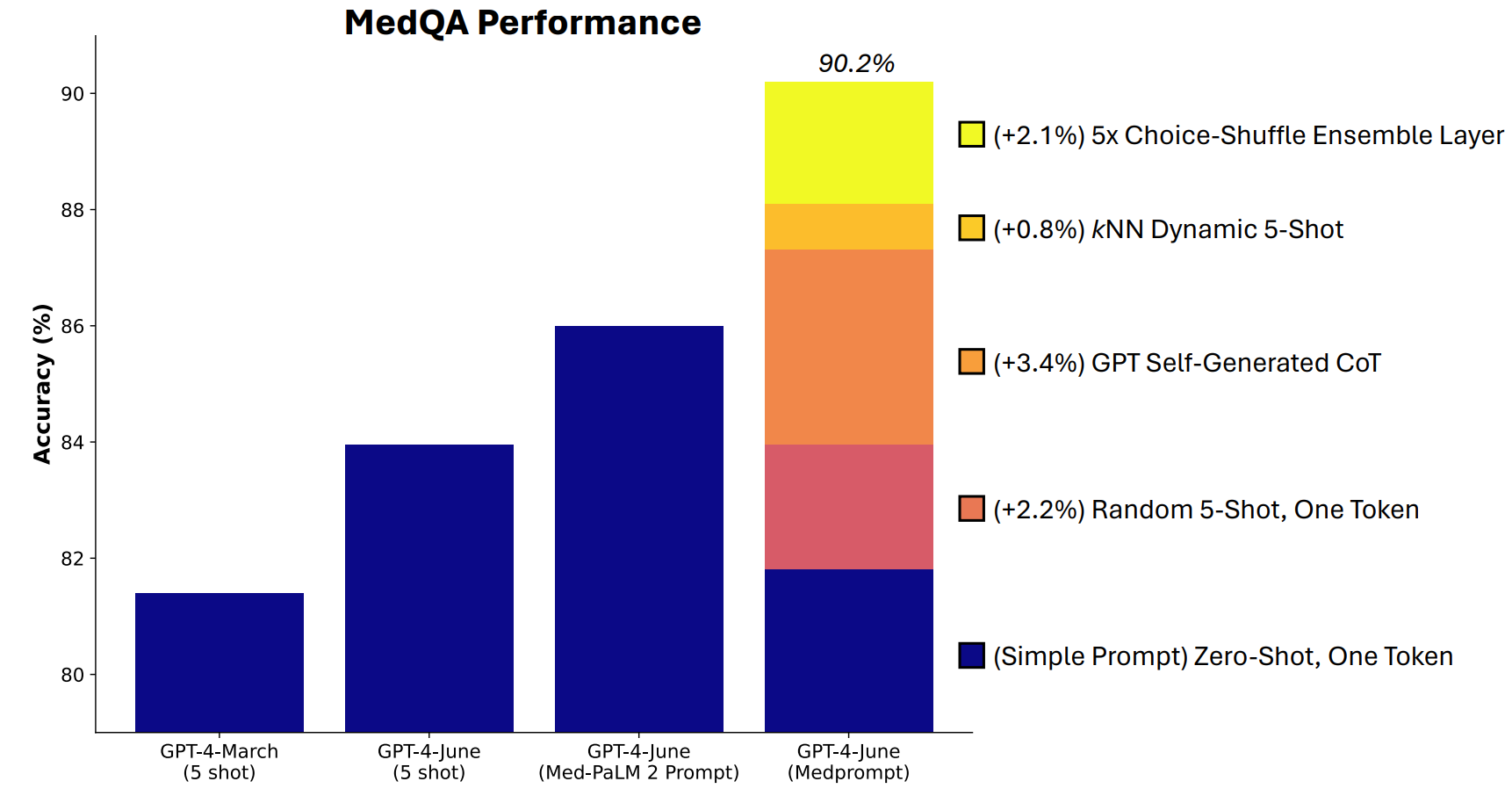
Microsoft-forskarna tänkte att om Medprompt fungerade bra i specialiserade medicinska tester skulle det också kunna förbättra GPT-4:s generalistiska prestanda. Och därmed återfick Microsoft och OpenAI skryträttigheterna med GPT-4 över Gemini Ultra.
Hur fungerar Medprompt?
Medprompt är en kombination av smarta prompttekniker i ett och samma program. Den bygger på tre huvudtekniker.
Dynamisk inlärning av få skott (DFSL)
"Few-shot learning" innebär att man ger GPT-4 några exempel innan man ber den att lösa ett liknande problem. När du ser en referens som "5-shot" betyder det att modellen fick 5 exempel. "Zero-shot" betyder att den var tvungen att svara utan några exempel.
I Medprompt-dokumentet förklaras att "för enkelhetens och effektivitetens skull är de få exempel som används för att uppmana till en viss uppgift vanligtvis fasta; de är oförändrade i alla testexempel."
Resultatet blir att de exempel som modellerna presenteras med ofta bara är relevanta eller representativa i stora drag.
Om din träningsuppsättning är tillräckligt stor kan du få modellen att titta igenom alla exempel och välja de som är semantiskt lika det problem som den måste lösa. Resultatet är att de få inlärningsexemplen är mer specifikt inriktade på ett visst problem.
Självgenererad tankekedja (CoT)
Chain of Thought (CoT) är ett utmärkt sätt att styra en LLM. När du uppmanar dem att "tänka efter noga" eller "lösa det steg för steg" blir resultaten mycket bättre.
Du kan bli mycket mer specifik i ditt sätt att styra tankekedjan som modellen ska följa, men det kräver manuell prompt engineering.
Forskarna fann att de "helt enkelt kunde be GPT-4 att generera tankekedjor för träningsexemplen". Deras tillvägagångssätt säger i princip till GPT-4: "Här är en fråga, svarsalternativen och det rätta svaret. Vilken CoT ska vi inkludera i en prompt som skulle komma fram till det här svaret?
Val Shuffle Ensembling
De flesta av MMLU:s riktmärkestester är flervalsfrågor. När en AI-modell svarar på dessa frågor kan den bli offer för positionell partiskhet. Med andra ord kan den gynna alternativ B över tid även om det inte alltid är rätt svar.
Choice Shuffle Ensembling blandar om svarsalternativens positioner och låter GPT-4 svara på frågan igen. Detta görs flera gånger och sedan väljs det mest konsekvent valda svaret som det slutliga svaret.
Kombinationen av dessa tre snabba tekniker är vad som gav Microsoft möjlighet att kasta lite skugga på Geminis resultat. Det kommer att bli intressant att se vilka resultat Gemini Ultra skulle uppnå om det använde ett liknande tillvägagångssätt.
Medprompt är spännande eftersom det visar att äldre modeller kan prestera ännu bättre än vi trodde om vi uppmanar dem på smarta sätt. Den extra processorkraft som krävs för dessa extra steg kanske dock inte gör det till ett genomförbart tillvägagångssätt i de flesta scenarier.



