Googles video som visade upp sin nya modell Geminis kapacitet var inget annat än fantastisk. Tyvärr är sanningen om hur bra Gemini är och vad den kan göra inte lika stor som marknadsföringshypen.
När vi först såg demovideon som visade Gemini interagera i realtid med presentatören blev vi helt överväldigade. Vi var så upprymda att vi missade några viktiga ansvarsfriskrivningar i början och accepterade videon till nominellt värde.
Texten i de första sekunderna av videon säger "Vi har spelat in filmer för att testa den på ett brett spektrum av utmaningar, visat den en serie bilder och bett den att resonera om vad den ser."
Vad som egentligen hände bakom kulisserna är orsaken till kritik som Google fick och de etiska frågor som den väcker.
Gemini tittade inte på en livevideo av presentatören som ritade en anka eller flyttade koppar runt. Inte heller svarade Gemini på de röstmeddelanden du hörde. Videon var en stiliserad marknadsföringspresentation av en enklare sanning.
I själva verket presenterades Gemini med stillbilder och textmeddelanden som var mer detaljerade än de frågor som du hör presentatören ställa.
En talesman för Google bekräftade att de ord du hör talas i videon är "riktiga utdrag från de faktiska uppmaningar som används för att producera Gemini-utmatningen som följer."
Så, detaljerade textmeddelanden, stillbilder och textsvar. Det Google faktiskt visade upp var funktionalitet som GPT-4 har haft i flera månader.
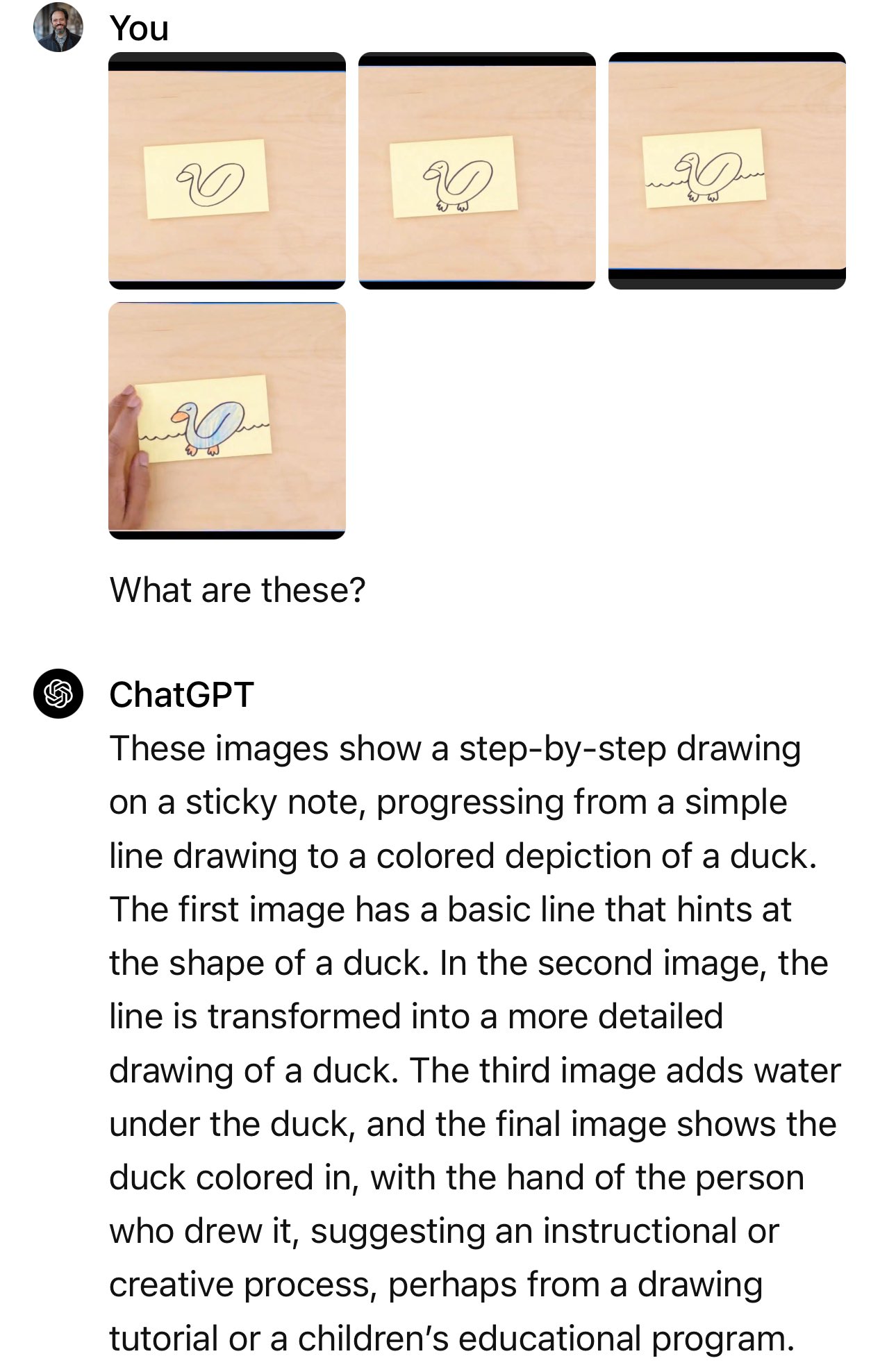
Googles blogginlägg visar de stillbilder och textmeddelanden som faktiskt användes.
I exemplet med bilen frågar presentatören: "Baserat på deras design, vilken av dessa skulle gå fortast?"
Den faktiska frågan som användes var: "Vilken av de här bilarna är mest aerodynamisk? Den till vänster eller den till höger? Förklara varför, med hjälp av specifika visuella detaljer."
Och när man återskapar experimentet på Bard, som Gemini nu styr över, blir det inte alltid rätt.

Jag ville verkligen tro att Gemini kunde följa bollen när de tre kopparna flyttades runt, men tyvärr är inte heller det sant.
Googles blogginlägg visar att det krävdes en hel del uppmaningar och förklaringar för demonstrationen av koppblandning.

Det är fortfarande imponerande att en AI-modell kan göra det här, men det är inte vad vi fick höra i videon.
Är det allt, Google?
Vi spekulerar bara här, men demonstrationen visade troligen resultat som Google fick med Gemini Ultra, som fortfarande inte har släppts.
Så när Gemini Ultra så småningom släpps ser det ut som om det kommer att kunna göra vad GPT-4 har gjort i flera månader. Implikationerna är inte stora.
Håller vi på att slå i taket när det gäller AI-kapacitet? För om de bästa AI-hjärnorna arbetar på Google så måste de ju driva på banbrytande innovation.
Eller var Google inte bara långsamma med att komma in i tävlingen utan kämpade för att hålla jämna steg med resten? De jämförelsetal som Google stolt visade upp visar att deras ännu inte släppta modell marginellt slår GPT-4 i vissa tester. Hur kommer det att gå mot GPT-5?
Eller kanske Googles marknadsavdelning gjorde en felbedömning med sin video, men Gemini Ultra kommer fortfarande att vara bättre än vi tror. Google säger att Gemini verkligen är multimodal och att den förstår video, vilket verkligen kommer att vara en första för LLM.
Vi har inte sett en LLM demonstrera videoförståelse ännu, men när vi gör det kommer det att vara värt att bli upphetsad över. Kommer det att vara Gemini Ultra eller GPT-5 som visar oss först?