

Elon Musk tillkännagav betalanseringen av xAI:s chatbot Grok och den första statistiken ger oss en uppfattning om hur den står sig mot andra modeller.
Den Grok chattbot är baserad på xAI:s gränsmodell Grok-1 som företaget utvecklat under de senaste fyra månaderna. xAI har inte sagt hur många parametrar den tränats med men gav några siffror för sin föregångare.
Grok-0, prototypen för den nuvarande modellen, tränades på 33 miljarder parametrar så vi kan nog anta att Grok-1 tränades på minst lika många.
Det låter inte mycket, men xAI hävdar att Grok-0:s prestanda "närmar sig LLaMA 2 (70B)-kapaciteten på standard LM-benchmarks" trots att den använde hälften så mycket träningsresurser.
I avsaknad av en parametersiffra får vi ta företaget på orden när det beskriver Grok-1 som "state-of-the-art" och att den är "betydligt kraftfullare" än Grok-0.
Grok-1 sattes på prov genom att utvärderas på dessa standardiserade riktmärken för maskininlärning:
- GSM8k: Ordproblem i matematik för mellanstadiet
- MMLU: Multidisciplinära flervalsfrågor
- HumanEval: Uppgift för att slutföra Python-kod
- MATH: Matematikproblem för högstadiet och gymnasiet skrivna i LaTeX
Här följer en sammanfattning av resultaten.
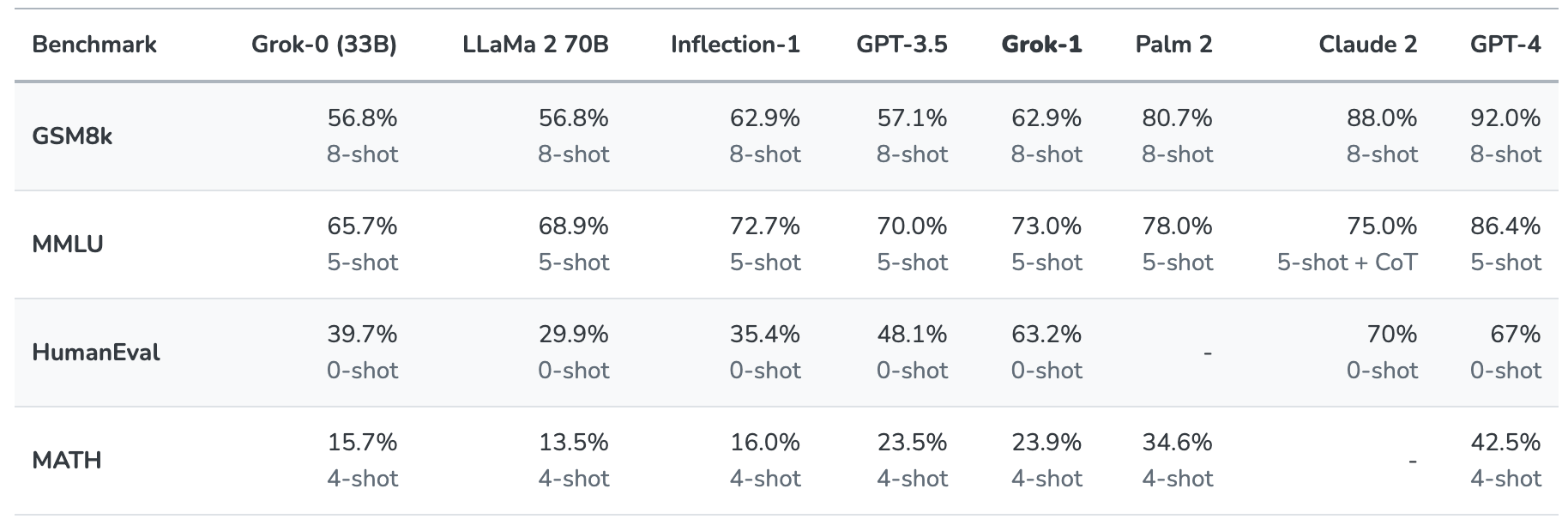
Resultaten är intressanta eftersom de ger oss åtminstone en uppfattning om hur Grok står sig i jämförelse med andra frontier-modeller.
xAI säger att dessa siffror visar att Grok-1 slår "alla andra modeller i sin beräkningsklass" och endast slogs av modeller som tränats med en "betydligt större mängd träningsdata och beräkningsresurser".
GPT-3.5 har 175 miljarder parametrar så vi kan anta att Grok-1 har mindre än så, men sannolikt mer än de 33 miljarder som prototypen har.
Grok-chatboten är avsedd att hantera uppgifter som att svara på frågor, hämta information, skriva kreativt och hjälpa till med kodning. Det är mer sannolikt att den används för kortare interaktioner än för snabba användningsfall på grund av dess mindre kontextfönster.
Med en kontextlängd på 8 192 har Grok-1 bara hälften av den kontext som GPT-3.5 har. Detta är en indikation på att xAI förmodligen avsåg att Grok-1 skulle byta ut en längre kontext mot bättre effektivitet.
Företaget säger att en del av dess nuvarande forskning är inriktad på "förståelse och hämtning av långa sammanhang", så nästa version av Grok kan mycket väl ha ett större sammanhangsfönster.
Det exakta datasetet som användes för att träna Grok-1 är inte klart men det inkluderade nästan säkert dina tweets på X, och Grok-chatbotten har också tillgång till internet i realtid.
Vi måste vänta på mer feedback från betatestare för att få en verklig känsla för hur bra modellen faktiskt är.
Kommer Grok att hjälpa oss att lösa livets, universums och alltings mysterier? Kanske inte riktigt än, men det är en underhållande början.



