

Luke Farritor, en 21-årig datavetenskapsstudent från University of Nebraska-Lincoln, har avslöjat texten i en förkolnad skriftrulle från det antika Herculaneum.
Rullen har varit oläslig sedan vulkanutbrottet år 79 e.Kr. som också uppslukade Pompeji. Farritors maskininlärningsalgoritm lyckades lokalisera grekiska bokstäver på den hoprullade papyrusen, inklusive ordet πορϕυρας (porphyras), som betyder "purpur".
Hans teknik gick ut på att identifiera små, nyanserade skillnader i ytstrukturen för att träna sitt neurala nätverk att upptäcka bläck, och i sin tur leterring.
"När jag såg den första bilden blev jag chockad", säger sa Federica Nicolardi, papyrolog från Neapels universitet. "Det var en dröm", fortsätter hon, "att jag faktiskt kan se något från insidan av en skriftrulle."
Rullarna, som begravdes av Vesuvius utbrott år 79 e.Kr., har förblivit i stort sett oåtkomliga på grund av sitt bräckliga tillstånd.
När de förkolnade rullarna rullas ut manuellt flagnar de sönder och forskarna befarar att innehållet kommer att förbli ett mysterium för alltid.

Nicolardi förklarade: "Det här är så galna föremål. De är alla skrynkliga och krossade."
Medvetna om utmaningen att tyda skriftrullarna har Vesuvius utmaning där olika priser delades ut, bland annat ett huvudpris på US$700.000 för den som lyckades tyda flera avsnitt i en skriftrulle.
Den 12 oktober meddelades att Farritor hade vunnit ett pris på $40.000 för att ha identifierat över 10 tecken i en liten del av papyrusen.
En annan deltagare, Youssef Nader från Free University of Berlin, fick $10.000 för sin andraplats.
Historikern Thea Sommerschield, som forskar om antikens Grekland och Rom, beskriver möjligheten att äntligen kunna urskilja bokstäver och ord i rullarna som "extremt spännande".
Sommerschield nämnde att tolkningen av dessa skulle kunna "revolutionera vår kunskap om antikens historia och litteratur" från regionen.
Det är inte första gången som forskare försöker läsa dessa gamla förkolnade skriftrullar. År 2019 försökte Brent Seales, professor i datavetenskap och specialiserad på virtuell läsning och bevarande av antika skriftrullar, att "virtuellt packa upp" rullarna med hjälp av röntgendatortomografi (CT).
År 2016 lyckades Seales med ett gammalt hebreiskt pergament som hittades 1970 i Ein Gedi, Israel, och avslöjade delar av Tredje Mosebok.
Rullarna från Herculaneum utgjorde dock en annan utmaning: bläcket, som består av träkol och vatten, stod inte ut i skanningarna.
Det var här Farritor lyckades genom att fokusera på en specifik subtil textur, kallad "crackle", för spår av bläck.
Farritor säger att "jag hoppade upp och ner" när hans algoritm visade fem bokstäver från ett nyligen släppt segment. "Herregud, det här kommer faktiskt att fungera", insåg han.
Kort därefter förfinade han sin modell och identifierade de tio bokstäver som krävdes för priset, med ordet "purpur" som inte tidigare identifierats i rullarna från Herculaneum.
Det stora priset i Vesuvius Challenge har ännu inte presenterats, men deadline är satt till den 31 december.
AI för avkodning av forntida språk
För sex årtusenden sedan bosatte sig sumerierna i Mesopotamien, landet som sträcker sig över floderna Tigris och Eufrat.
I denna region, som omfattar dagens Irak, Kuwait, Turkiet och Syrien, skedde en utveckling från små jordbrukssamhällen till storslagna stadscivilisationer. Städer som Uruk växte fram med invecklade kanaler, bevattningsanläggningar och ledningscentraler. Det var en kritisk era för mänsklighetens framsteg och utveckling.
Sumererna skrev med ett skript som kallas kilskrift. Detta skriftsystem krävde att man pressade vass i lera, vilket genererade komplexa logo-syllabiska inskriptioner. Kilskrift är inte ett språk - det är ett skript som omfattar cirka 15 språk under tre årtusenden.

Kilskriften användes främst som ett administrativt verktyg för att t.ex. registrera boskap eller transaktioner, men omkring 2700 f.Kr. uppstod ett brett spektrum av mer filosofiska och kreativa skrifter.
En av de mest uppmärksammade av dessa skrifter är Gilgamesh-eposetsom sträcker sig över tolv tabletter.
Enrique Jiménez från Ludwig Maximilians University i München säger: "Halva mänsklighetens historia finns inkapslad i dessa kilskriftstavlor."
Men endast 75 individer, enligt Ny vetenskapsmankan avkoda kilskrift trots att det finns tiotusentals oöversatta tavlor i världen.
Maskininlärning hjälper nu forskare att nysta i de berättelser som finns inristade i stentavlorna och hjälper dem att fylla i luckor och ordna texterna kronologiskt för att upptäcka mer om hur de gamla sumererna levde.
Maskininlärningens roll i dekryptering av forntida text
Enrique Jiménez och hans team grundade Elektronisk babylonisk litteratur, ett samarbete mellan arkeologer, datavetare och historiker.
För att analysera kilskriftstavlorna använde teamet en maskininlärningsteknik som ursprungligen utformats för jämförelse av gensekvenser. Denna AI förutspår innehållet i saknade avsnitt och gränserna vid vilka fragment anpassas.
Denna teknik ledde till upptäckter som saknade delar av Gilgamesheposet och en nyupptäckt mesopotamisk genre som beskrev pedagogiska parodier och skämt för barn.
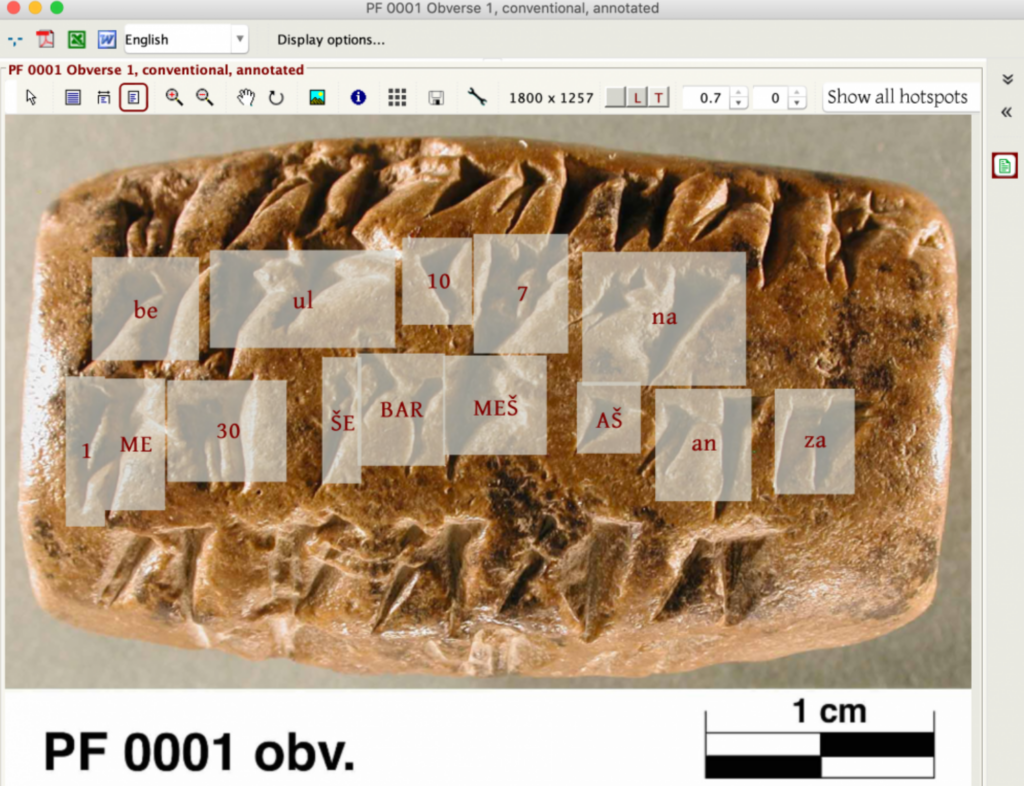
År 2020, en separat modell, DeepScribetränades på 6.000 annoterade bilder från Persepolis Fortification Archivesom innehåller cirka 100.000 symboler från det elamitiska språket (från dagens Iran), daterat till cirka 500 f.Kr.
Med hjälp av resurser från UChicago Research Computing Center tränade Krishnan och Eddie Williams en modell som kunde avkoda dessa tecken med en imponerande noggrannhet på 80%.
Teamet har för avsikt att utveckla DeepScribe till ett mångsidigt avkodningsverktyg som kan omskolas till andra språk än elamit.
DeepMind har också undersökt avkodning av forntida språk med hjälp av maskininlärning - i det här fallet skadade antika grekiska tabletter.
Namngiven Ithacahar denna modell återställt texter med 72% precision, uppskattat deras ålder inom tre decennier och till och med gissat deras ursprung med 71% noggrannhet.

Ithacas utbildning omfattade 60.000 texter från 700 f.Kr. till 500 e.Kr. som märkts med data om tid och plats i 84 antika territorier.
Samspelet mellan gamla texter och avancerad AI visar att inte ens tusenåriga mysterier är immuna mot den moderna teknikens framsteg.
Genom att blanda det gamla med det nya bevarar forskarna både historien och skapar tidigare okända arkeologisk kunskap.
Dessa genombrott understryker de obegränsade möjligheterna när vi förenar mänsklig nyfikenhet med teknisk skicklighet och visar att det finns en ny lins genom vilken vi kan se underverken i vårt kollektiva förflutna.




{kind=link}