

Digital kolonialism innebär att teknikjättar och mäktiga aktörer dominerar det digitala landskapet och formar flödet av information, kunskap och kultur så att det tjänar deras intressen.
Denna dominans handlar inte bara om att kontrollera den digitala infrastrukturen utan också om att påverka de berättelser och kunskapsstrukturer som definierar vår digitala tidsålder.
Digital kolonialism, och nu AI-kolonialism, är allmänt erkända termer, och institutioner som MIT har forskat och skrivit om dem i stor utsträckning.
Toppforskare från Anthropic, Google, DeepMind och andra teknikföretag har öppet diskuterat AI:s begränsade möjligheter att tjäna människor med olika bakgrund, särskilt med hänvisning till förspänning i system för maskininlärning.
System för maskininlärning fdata som de tränas på - data som inte alltid återspeglar de data som de tränas på.kan ses som en produkt av vår digitala tidsanda - en samling av rådande berättelser, bilder och idéer som dominerar onlinevärlden.
Men vem får forma dessa informationskrafter? Vems röster förstärks och vems röster dämpas?
När AI lär sig från träningsdata ärver den specifika världsbilder som inte nödvändigtvis stämmer överens med eller representerar globala kulturer och erfarenheter. Dessutom formas de kontroller som styr resultatet av generativa AI-verktyg av underliggande sociokulturella vektorer.
Detta har lett till att utvecklare som Anthropic söka demokratiska metoder att forma AI:s beteende med hjälp av offentliga åsikter.
Som Jack Clark, Anthropics policychef, beskrev en nyligen genomfört experiment från sitt företag: "Vi försöker hitta ett sätt att utveckla en konstitution som utvecklas av en hel massa tredje parter, snarare än av människor som råkar arbeta på ett labb i San Francisco."
Dagens paradigm för generativ AI-utbildning riskerar att skapa en digital ekokammare där samma idéer, värderingar och perspektiv ständigt förstärks, vilket ytterligare befäster dominansen hos dem som redan är överrepresenterade i datan.
I takt med att AI integreras i komplexa beslutsprocesser, från social välfärd och rekrytering till finansiella beslut och medicinska diagnoserleder den ensidiga representationen till fördomar och orättvisor i den verkliga världen.
Dataseten är geografiskt och kulturellt placerade
En ny studie av Data Provenance Initiative undersökte 1 800 populära dataset avsedda för NLP (Natural Language Processing), en disciplin inom AI som fokuserar på språk och text.
NLP är den dominerande maskininlärningsmetodiken bakom stora språkmodeller (LLM), inklusive ChatGPT och Meta's Llama-modeller.
Studien visar på en västcentrerad språkrepresentation i olika dataset, där engelska och västeuropeiska språk definierar textdata.
Språk från länder i Asien, Afrika och Sydamerika är markant underrepresenterade.
Följaktligen kan LLM inte hoppas på att korrekt representera de kulturella och språkliga nyanserna i dessa regioner i samma utsträckning som västerländska språk.
Även när språk från den globala södern verkar vara representerade kommer källan och dialekten för språket främst från nordamerikanska eller europeiska skapare och webbkällor.

A föregående Antropiskt experiment fann att språkbyte i modeller som ChatGPT fortfarande gav upphov till västcentrerade åsikter och stereotyper i konversationer.
Anthropic-forskarna drog slutsatsen att "om en språkmodell på ett oproportionerligt sätt representerar vissa åsikter, riskerar den att få potentiellt oönskade effekter som att främja hegemoniska världsbilder och homogenisera människors perspektiv och övertygelser".
Data Provenance-studien dissekerade också det geografiska landskapet för datasetkurering. Akademiska organisationer framstår som de främsta drivkrafterna och bidrar till 69% av dataseten, följt av industrilaboratorier (21%) och forskningsinstitutioner (17%).
De största bidragsgivarna är AI2 (12,3%), University of Washington (8,9%) och Facebook AI Research (8,4%).
A separat studie 2020 visar att hälften av de dataset som använts för AI-utvärdering i cirka 26.000 forskningsartiklar härrör från så få som 12 toppuniversitet och teknikföretag.
Även här visade det sig att geografiska områden som Afrika, Syd- och Centralamerika samt Centralasien var sorgligt underrepresenterade, se nedan.
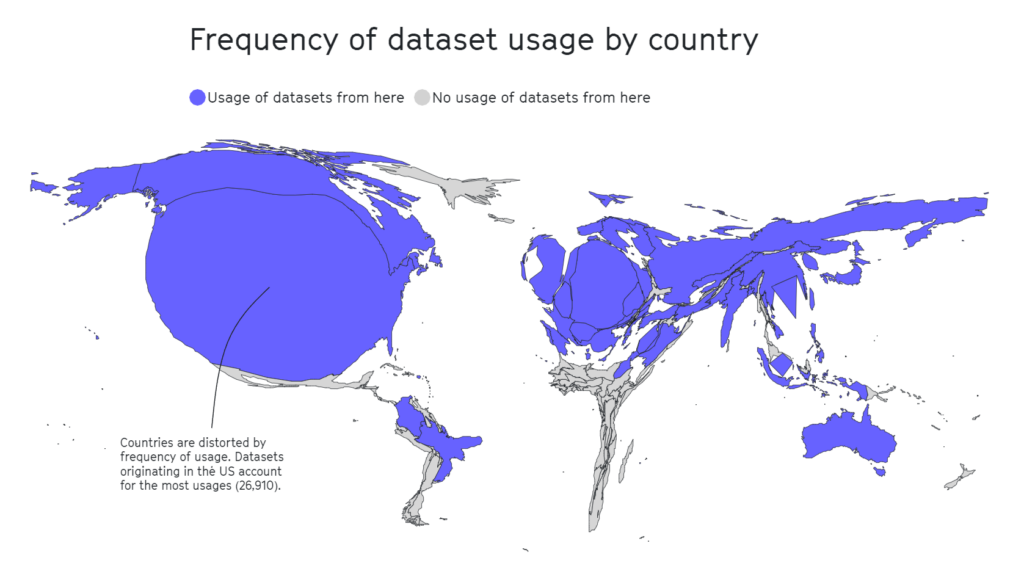
I annan forskning har inflytelserika dataset som MIT:s Tiny Images eller Labeled Faces in the Wild främst innehållit bilder av vita västerländska män, med cirka 77,5% män och 83,5% vithyade individer i fallet med Labeled Faces in the Wild.
När det gäller Tiny Images, en 2020-analys av The Register fann att många Tiny Images innehöll obscena, rasistiska och sexistiska etiketter.
Antonio Torralba från MIT sa att de inte var medvetna om etiketterna, och datasetet raderades. Torralba sa: "Det är uppenbart att vi borde ha granskat dem manuellt."
Engelska dominerar ekosystemet för AI
Pascale Fung, datavetare och chef för Center for AI Research vid Hong Kong University of Science and Technology, diskuterade de problem som är förknippade med hegemonisk AI.
Fung hänvisar till mer än 15 forskningsrapporter som undersöker flerspråkighetskunskaperna hos LLM:er och som genomgående visar på brister, särskilt när det gäller att översätta engelska till andra språk. Språk med icke-latinskt alfabet, som koreanska, avslöjar till exempel LLM:s begränsningar.
Förutom dåligt flerspråkigt stöd, andra studier tyder på att majoriteten av riktmärkena och måtten för bias har utvecklats med engelskspråkiga modeller i åtanke.
Det finns få riktmärken för icke-engelskspråkig bias, vilket leder till en betydande lucka i vår förmåga att bedöma och korrigera bias i flerspråkiga språkmodeller.
Det finns tecken på förbättringar, till exempel Googles ansträngningar med sin PaLM 2-språkmodell och Meta's Massivt flerspråkigt tal (MMS) som kan identifiera mer än 4.000 talade språk, 40 gånger mer än andra metoder. MMS är dock fortfarande på experimentstadiet.
Forskare skapar olika flerspråkiga dataset, men den överväldigande mängden engelsk textdata, som ofta är gratis och lättillgänglig, gör den till det självklara valet för utvecklare.
Bortom data: strukturella frågor inom AI-arbete
MIT:s omfattande genomgång av AI-kolonialism uppmärksammade en relativt dold aspekt av AI-utvecklingen - exploaterande arbetsmetoder.
AI har lett till en kraftig ökning av efterfrågan på tjänster för datamärkning. Företag som Appen och Sama har vuxit fram som nyckelaktörer och erbjuder tjänster för att tagga text, bilder och videor, sortera foton och transkribera ljud för att mata maskininlärningsmodeller.
Mänskliga dataspecialister märker också innehållstyper manuellt, ofta för att sortera data som innehåller olagligt, otillåtet eller oetiskt innehåll, till exempel beskrivningar av sexuella övergrepp, skadligt beteende eller andra olagliga aktiviteter.
Även om AI-företag automatiserar vissa av dessa processer är det fortfarande viktigt att hålla "människor i loopen" för att säkerställa att modellerna är korrekta och att säkerheten efterlevs.
Marknadsvärdet för detta "spökarbete", som antropologen Mary Gray och samhällsvetaren Siddharth Suri kallar det, beräknas uppgå till skjuta i höjden till $13,7 miljarder år 2030.
Spökarbete innebär ofta att man utnyttjar billig arbetskraft, särskilt från ekonomiskt utsatta länder. Venezuela, till exempel, har blivit en viktig källa till AI-relaterad arbetskraft på grund av landets ekonomiska kris.
När landet brottades med den värsta ekonomiska katastrofen i fredstid och astronomisk inflation vände sig en betydande del av den välutbildade och internetanslutna befolkningen till crowd-working-plattformar för att överleva.
Kombinationen av en välutbildad arbetskraft och ekonomisk desperation gjorde Venezuela till en attraktiv marknad för företag som sysslar med datamärkning.
Detta är inte en kontroversiell fråga - när MIT publicerar artiklar med titlar som "Artificiell intelligens skapar en ny kolonial världsordning", som hänvisar till scenarier som detta, är det tydligt att vissa i branschen försöker dra undan ridån för dessa underhand arbetsmetoder.
Som MIT rapporterar har den spirande AI-industrin för många venezuelaner varit ett tveeggat svärd. Samtidigt som den gav en ekonomisk livlina mitt i desperationen, utsatte den också människor för exploatering.
Julian Posada, doktorand vid University of Toronto, lyfter fram den "enorma maktobalansen" i dessa arbetsarrangemang. Plattformarna dikterar reglerna, vilket ger arbetstagarna lite att säga till om och begränsad ekonomisk kompensation trots utmaningar på jobbet, t.ex. exponering för störande innehåll.
Denna dynamik påminner kusligt mycket om historiska koloniala metoder där imperier utnyttjade arbetskraften i utsatta länder, drog ut vinster och övergav dem när möjligheten minskade, ofta för att "bättre värde" fanns tillgängligt någon annanstans.
Liknande situationer har observerats i Nairobi, Kenya, där en grupp tidigare innehållsmoderatorer som arbetade på ChatGPT lämnat in en framställning med den kenyanska regeringen.
De hävdade att de utsatts för "exploaterande förhållanden" under sin tid hos Sama, ett USA-baserat företag för dataanmärkningstjänster som anlitats av OpenAI. Framställarna hävdade att de utsattes för störande innehåll utan tillräckligt psykosocialt stöd, vilket ledde till allvarliga psykiska problem, bland annat PTSD, depression och ångest.

Dokument recenserad av TIME framgick att OpenAI hade tecknat avtal med Sama till ett värde av cirka $200 000. Dessa kontrakt omfattade märkning av beskrivningar av sexuella övergrepp, hatpropaganda och våld.
Påverkan på arbetarnas psykiska hälsa var djupgående. Mophat Okinyi, en tidigare moderator, talade om de psykologiska konsekvenserna och beskrev hur exponering för grafiskt innehåll ledde till paranoia, isolering och betydande personliga förluster.
Lönerna för ett sådant plågsamt arbete var chockerande låga - en talesperson för Sama uppgav att arbetarna tjänade mellan $1,46 och $3,74 i timmen.
Motstånd mot digital kolonialism
Om AI-industrin har blivit en ny gräns för digital kolonialism, så blir motståndet redan mer sammanhållet.
Aktivister, ofta med stöd från AI-forskare, förespråkar ansvarsutkrävande, policyförändringar och utveckling av teknik som prioriterar lokalsamhällenas behov och rättigheter.
Nanjala Nyabolas Projekt för digitala rättigheter på kiswahili är ett innovativt exempel på hur lokala gräsrotsprojekt kan installera den infrastruktur som krävs för att skydda samhällen från digital hegemoni.
Projektet tar hänsyn till de västerländska reglernas hegemoni när en grupps digitala rättigheter definieras, eftersom alla inte skyddas av de lagar om immateriella rättigheter, upphovsrätt och integritet som många av oss tar för givna. Detta innebär att en betydande andel av världens befolkning kan utnyttjas av teknikföretag.
Nyabola och hennes team insåg att diskussioner om digitala rättigheter försvåras om människor inte kan kommunicera på sina modersmål och översatte därför viktiga termer inom digitala rättigheter och teknik till språket kiswahili, som främst talas i Tanzania, Kenya och Moçambique.
Nyabola Beskrivning av projektet"Under den processen [av Huduma Namba-initiativet] hade vi inte riktigt språket och verktygen för att förklara för icke-specialiserade eller icke-engelskspråkiga grupper i Kenya vad initiativet innebar."
I ett liknande gräsrotsprojekt hade Te Hiku Media, en ideell radiostation som främst sänder på māori-språket, en stor databas med inspelningar som sträckte sig över flera decennier, varav många ekade av förfäders fraser som inte längre talades.
Vanliga taligenkänningsmodeller, liknande LLM-modeller, tenderar att underleverera när de uppmanas att använda olika språk eller engelska dialekter.
Den Te Hiku Media samarbetade med forskare och öppen källkodsteknik för att träna upp en taligenkänningsmodell som var skräddarsydd för maorispråket. Māori-aktivisten Te Mihinga Komene bidrog med cirka 4 000 fraser till de otaliga andra som deltog i projektet.
Den resulterande modell och data skyddas enligt lagen om Kaitiakitanga Licens - Kaitiakitanga är ett maori-ord som saknar en specifik engelsk definition men som kan liknas vid "förmyndare" eller "vårdnadshavare".
Keoni Mahelona, en av grundarna av Te Hiku Media, sa på ett gripande sätt: "Data är den sista gränsen för kolonisering."
Dessa projekt har inspirerat andra urfolk och ursprungsbefolkningar som utsätts för påtryckningar från digital kolonialism och andra former av sociala omvälvningar, till exempel mohawkfolket i Nordamerika och Hawaiis ursprungsbefolkningar.
I takt med att AI med öppen källkod blir billigare och lättare att få tillgång till bör det bli enklare att iterera och finjustera modeller med hjälp av unika lokala dataset, vilket förbättrar den tvärkulturella tillgången till tekniken.
AI-industrin är fortfarande ung, men nu är det dags att lyfta fram dessa utmaningar så att människor tillsammans kan utveckla lösningar.
Lösningarna kan vara både på makronivå, i form av regleringar, policyer och metoder för utbildning i maskininlärning, och på mikronivå, i form av lokala projekt och gräsrotsprojekt.
Tillsammans kan forskare, aktivister och lokalsamhällen hitta metoder för att säkerställa att AI gynnar alla.



