

Nvidia tillkännagav en ny programvara med öppen källkod som enligt företaget kommer att öka inferensprestandan på H100 GPU:erna.
En stor del av den nuvarande efterfrågan på Nvidias GPU:er är att bygga datorkraft för att träna nya modeller. Men när de väl är utbildade måste dessa modeller användas. Inferens i AI hänvisar till förmågan hos en LLM som ChatGPT att dra slutsatser eller göra förutsägelser från data som den har utbildats på och generera utdata.
När du försöker använda ChatGPT och ett meddelande dyker upp om att servrarna är ansträngda beror det på att datorhårdvaran kämpar för att hålla jämna steg med efterfrågan på inferens.
Nvidia säger att deras nya mjukvara, TensorRT-LLM, kan få deras befintliga hårdvara att köra mycket snabbare och dessutom mer energieffektivt.
Programvaran innehåller optimerade versioner av de mest populära modellerna, inklusive Meta Llama 2, OpenAI GPT-2 och GPT-3, Falcon, Mosaic MPT och BLOOM.
Den använder några smarta tekniker som mer effektiv batchning av inferensuppgifter och kvantiseringstekniker för att uppnå prestandaförbättringen.
LLM:er använder i allmänhet 16-bitars flyttalsvärden för att representera vikter och aktiveringar. Kvantisering tar dessa värden och reducerar dem till 8-bitars flyttalsvärden under inferens. De flesta modeller lyckas behålla sin noggrannhet med denna reducerade precision.
Företag som har datainfrastruktur baserad på Nvidias H100 GPU:er kan förvänta sig en enorm förbättring av inferensprestandan utan att behöva spendera ett öre genom att använda TensorRT-LLM.
Nvidia använde ett exempel där man körde en liten öppen källkodsmodell, GPT-J 6, för att sammanfatta artiklar i CNN/Daily Mail-datasetet. Deras äldre A100-chip används som baslinjehastighet och jämförs sedan med H100 utan och sedan med TensorRT-LLM.
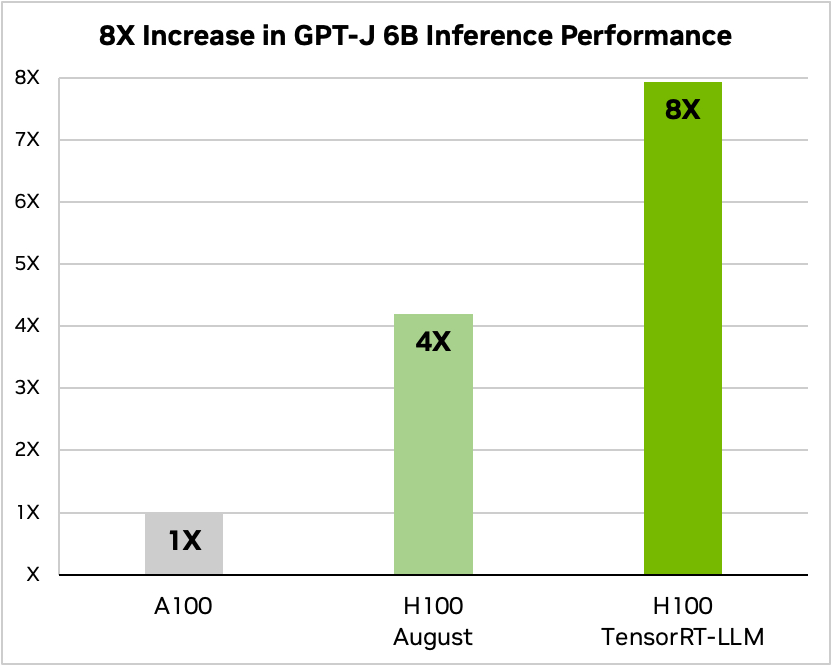
Källa: Nvidia
Och här är en jämförelse när du kör Meta's Llama 2
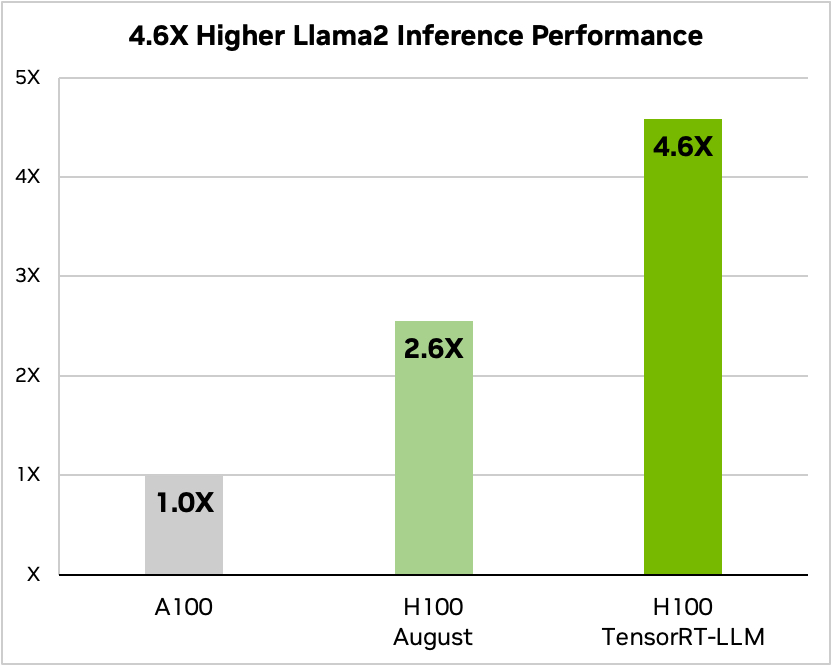
Källa: Nvidia
Nvidia säger att testerna visar att beroende på modell använder en H100 som kör TensorRT-LLM mellan 3,2 och 5,6 gånger mindre energi än en A100 under inferens.
Om du kör AI-modeller på H100-hårdvara innebär det inte bara att din inferensprestanda nästan kommer att fördubblas, utan även att din energiräkning kommer att bli mycket lägre när du har installerat den här programvaran.
TensorRT-LLM kommer också att göras tillgängligt för Nvidias Grace Hopper Superchips men företaget har inte släppt några prestandasiffror för GH200 med den nya programvaran.
Den nya programvaran var ännu inte klar när Nvidia lät sin superchip GH200 genomgå industristandarden MLPerf AI:s prestandatester. Resultaten visade att GH200 presterade upp till 17% bättre än en H100 SXM med ett enda chip.
Om Nvidia uppnår ens en blygsam ökning av inferensprestandan med TensorRT-LLM med GH200, kommer det att sätta företaget långt framför sina närmaste rivaler. Att vara säljare för Nvidia måste vara det enklaste jobbet i världen just nu.



