
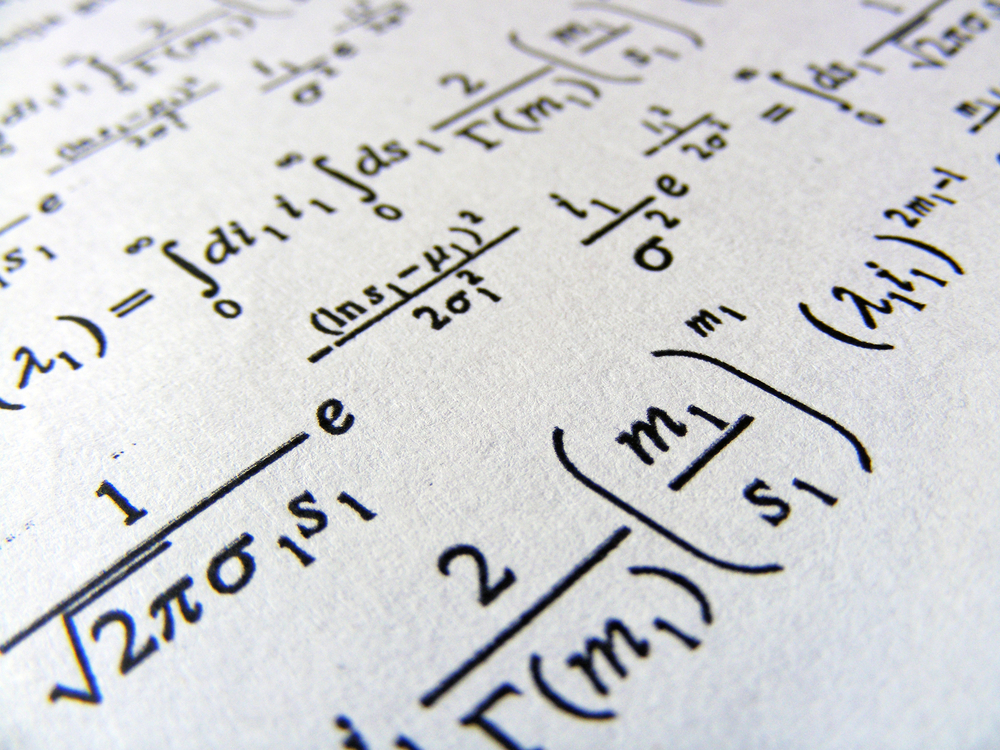
Meta har utvecklat en ny AI-modell som heter Nougat som på ett tillförlitligt sätt kan omvandla vetenskaplig text till maskinläsbar text.
Om du någonsin har försökt läsa ett vetenskapligt forskningsdokument så förstår du varför det är svårt att bearbeta det elektroniskt. Nuvarande OCR-verktyg (Optical Character Recognition) analyserar texten rad för rad.
Det är bra för rent textbaserade dokument, men vetenskapliga artiklar lägger till en nivå av komplexitet som dessa standardverktyg inte kan hantera.
Vetenskapliga artiklar innehåller matematiska och vetenskapliga symboler och formler som ofta läggs till som subskriptioner eller superscripts. Även de bästa OCR-programmen har problem med att fånga dessa korrekt.
Det som gör det ännu mer utmanande är att många av dessa forskningsrapporter är dåligt skannade och att originalen inte längre finns tillgängliga. Nougat, som står för Neural Optical Understanding for Academic Documents, är redo att anta utmaningen.
Istället för att skanna rad för rad bearbetar Nougat hela sidan med hjälp av en variant av Meta's Vision Transformer för bildanalys. Modellen tränades på en datamängd med artiklar som publicerats på PubMed Central och arXiv som hade motsvarande LaTeX-källkod.
LaTeX är en programvara som används för att skriva vetenskapliga artiklar som kräver komplexa formler och matematiska symboler. Modellen tränades genom att titta på bilden av papperet och jämföra den med koden som genererade den komplexa texten.
Här är ett exempel på ett av Metas experiment med att digitalisera ett gammalt forskningspapper.

Källa: Meta
Det finns några mer imponerande exempel på Facebook Forskningssida.
Nougat är inte perfekt, men det uppnådde ändå en BLEU-poäng på över 91% och en noggrannhet på över 96% med löpande text. BLEU-poängen mäter likheten mellan den maskinöversatta texten och en uppsättning referensöversättningar av hög kvalitet.
För formler och tabeller gick det lite sämre med en noggrannhet på drygt 75%. Det är fortfarande mycket bättre än konkurrerande modeller som GROBID som bara lyckas få rätt 11% av tiden.
Det finns miljontals sidor med forskning som inte är indexerbara eller sökbara eftersom de bara kan läsas effektivt av människor. Nougat ändrar på detta genom att tillåta att även dåligt skannade forsknings-PDF:er konverteras till maskinläsbar text.
Som med så många av sina andra nya verktyg har Meta gjort den här fritt tillgänglig på GitHub. Det kan dock finnas en viss grad av egenintresse i denna utveckling. När gamla forskningsrapporter blir maskinläsbara blir de tillgängliga för utbildning av andra AI-modeller.
Det kommer att bli intressant att se vilka sedan länge förlorade forskningspärlor som återupptäcks med Nougat.



