

Konstnärer och kreatörer ställer AI-utvecklare till svars för potentiella upphovsrättsintrång.
Skriv in en uppmaning i en AI-bildgenerator som DALL-E, MidJourney eller Stable Diffusion, och den kommer att producera en till synes unik bild inom bara några sekunder.
Trots sin uppenbara unikhet är tDessa bilder genereras från miljarder andra bilder genom vad som kan beskrivas som en komplex digital collageteknik.
Källbilderna hämtas från "offentliga" eller "öppna" källor.
Om du frågar ChatGPT hur en bildgenerator som DALL-E fungerar kommer den att säga något i stil med: "Tänk på DALL-E som en superavancerad digital konstnär som har sett miljontals bilder och kan rita en ny utifrån din beskrivning och försöka göra den så exakt som möjligt. Den gör detta genom att blanda och matcha element som den har lärt sig från sina tidigare 'observationer'."
Det är ungefär som att gå runt på världens konstgallerier och ta bilder av varje verk - fast man kan inte bli utslängd.
På internet finns det inga säkerhetsvakter och kameror som övervakar människor för att förhindra piratkopiering eller stöld, och dataskrapning - som innebär att man samlar in data från internet med hjälp av robotar - har alltid varit ett oklart juridiskt område.
Konstnärer hävdar att träning av AI för text-till-bild på offentliga dataset är likvärdigt med världens största konstkupp.
Hur känns det för konstnärer med AI-detektorer?
För vissa framgångsrika konstnärer, vars verk har kopierats tusentals eller till och med miljontals gånger, har effekterna av AI-genererad konst gjort det svårt att skilja mellan deras egna verk och AI-kopior.
De estetiska skillnaderna är helt enkelt för små, vilket förmodligen beror på att populära bilder förekommer i stor utsträckning i dataset.
Bland dem finns Greg Rutowski, som sa: "Mitt arbete har använts i AI mer än Picasso."

Rutowkis fantasyillustrationer förekommer i franchises som Dungeons and Dragons och Magic: The Gathering och kan replikeras via text-till-bild-generatorer genom att helt enkelt lägga till konstnärens namn till uppmaningen, t.ex. "Skapa en drake som slåss mot ett troll i Greg Rutowskis stil".
Han berättade för BBC"Den första månaden jag upptäckte det insåg jag att det helt klart kommer att påverka min karriär och att jag inte kommer att kunna känna igen och hitta mina egna verk på internet", och tillade: "Resultaten kommer att förknippas med mitt namn, men det kommer inte att vara min bild. Den kommer inte att vara skapad av mig. Så det kommer att skapa förvirring för människor som upptäcker mina verk."
Han fortsatte: "Allt som vi har arbetat med i så många år har tagits ifrån oss så enkelt med AI."
Det sista påståendet träffar verkligen målet, eftersom AI:s reproduktion av komplexa, begåvade verk tar bara några sekunder, vilket inte bara innebär att konstnärernas verk blir överflödiga, utan också att de färdigheter som använts för att skapa dem går förlorade.
Mänsklighetens lbrist på autentiska färdigheter och kunskaper är en av AI:s mest akuta risker, kallad "försvagning," illustreras av Disneyfilmen WALL-E, där människor förlorar förmågan att röra sig på grund av tekniken.
En annan konstnär som uttalat sig om att AI reproducerar deras verk är Kelly McKernan, en illustratör baserad i Tennessee som upptäckte att mer än 50 av hennes konstverk hade listats som träningsdata på Large-scale Artificial Intelligence Open Network (LAION).
Du kan söka bland cirka 5,8 miljarder bilder som finns i AI-träningsuppsättningar med verktyget "Har jag fått någon utbildning?" och det var så McKernan kom i kontakt med hennes arbete.
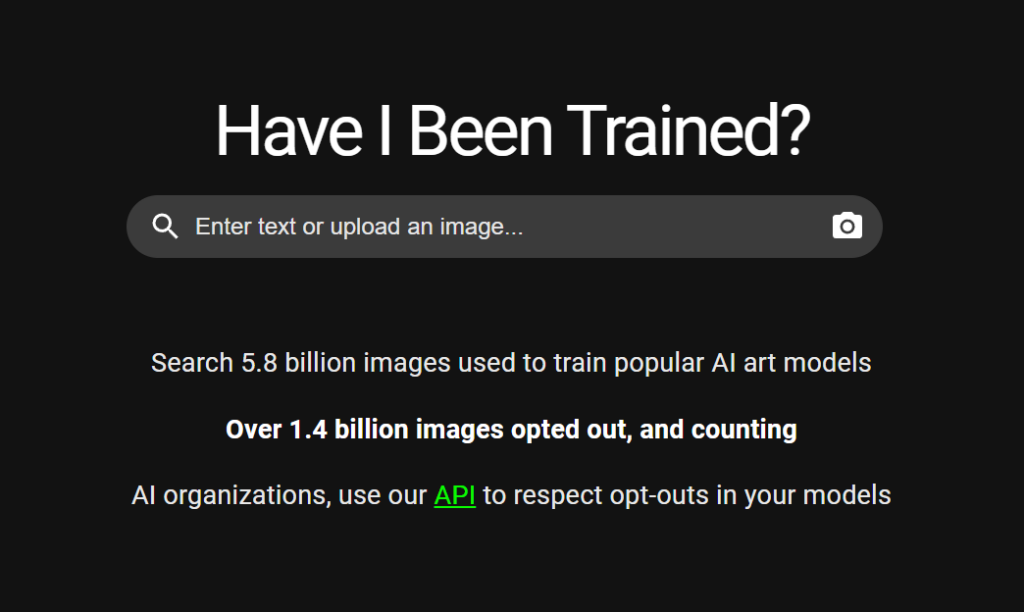
LAION är en ideell organisation som skapar modeller och dataset med öppen källkod, varav många har använts för att träna högprofilerade text-till-bild-modeller, inklusive Stable Diffusion och Imagen.
"Plötsligt fick alla dessa målningar som jag hade en personlig relation till och en resa med en ny innebörd, och det förändrade min relation till konstverken", säger McKernan.
Rättsliga tvister pågår
McKernan, tillsammans med konstnärskollegorna Sarah Anderson och Karla Ortiz, har vidtagit rättsliga åtgärder mot Stability AI, DeviantArt och Midjourney.
Deras stämningsansökan ansluter sig till en våg av rättsliga åtgärder mot AI-företag från både författare och bildkonstnärer.
Även större företag stämmer eller planerar att stämma AI-utvecklare, däribland Getty Images, som hävdade att Stability AI olovligen hade kopierat och bearbetat 12 miljoner av deras bilder utan tillstånd.
McKernan sa: "Som det är nu kan upphovsrätten bara tillämpas på min fullständiga bild. Jag hoppas att den [stämningen] uppmuntrar till skydd för konstnärer så att AI inte kan användas för att ersätta oss. Om vi vinner hoppas jag att många konstnärer får betalt. Det är gratis arbetskraft och vissa människor tjänar pengar på att utnyttja den."
McKernans stil, som du kan se nedan, har efterfrågats i cirka 12.000 MidJourney-meddelanden.
Visa detta inlägg på Instagram
Ett grundläggande problem här är att upphovsrättslagstiftningen helt enkelt inte var byggd för AI-eran.
Liam Budd från scenkonst- och underhållningsfacket Equity argumenterade för uppdaterade lagar som återspeglar de potentiella affärsmöjligheter som generativ AI erbjuder.
Han uttalade"Vi behöver en tydligare lagstiftning och driver en kampanj för att uppdatera upphovsrättslagen."
Som svar på den ökande vågen av AI-drivna upphovsrättsintrång har olika jurisdiktioner, till exempel EU, föreslagit att AI-utvecklare ska offentliggöra allt upphovsrättsskyddat material som används för träning.
Kommer det att räcka? Har AI-utvecklare redan visat att de sannolikt kommer att komma undan med det?
De flesta av dessa dataset är trots allt redan sammanställda, och AI-företagen skulle kunna hävda att de bara uppdaterar modeller för att kringgå behovet av att deklarera upphovsrättsskyddat material.
Har stämningarna en solid rättslig grund?
Denna nuvarande omgång av grupptalan kretsar i stort sett kring två argument.
- För det första påstås att bolagen har gjort intrång i konstnärers upphovsrätt genom att använda deras verk utan tillstånd.
- För det andra påståendet att AI-utdata i huvudsak är derivatinnehåll på grund av att de ingår i träningsdata.
Tillämpningen av dessa argument skiljer sig åt över världen, till exempel i USA, där lagarna om "fair use" i allmänhet är mer liberala än i EU. Detta komplicerar upphovsrättslandskapet för AI ytterligare. Om företag är verksamma i Storbritannien kan det till exempel vara svårare för dem att hävda "fair use".
Dessutom stäms generativa AI-företag, inte de enheter som sammanställer dataseten, till exempel LAION i fallet med MidJourney. Eliana Torres, immaterialrättsjurist på advokatbyrån Nixon Peabody, påpekar att om LAION skapade datasetet så skedde det påstådda intrånget vid den tidpunkten, inte när datasetet användes för att träna modellerna.
Att bevisa att AI-genererade verk är reproduktioner av originalverk är en utmaning på grund av AI:s komplexa natur, som använder algoritmisk bearbetning för att bryta ner och återmontera bilder.
Regleringsorganen har överraskats av de juridiska konsekvenserna av generativ AI, och även om tillfälliga lösningar som automatiserade filter och opt-out-bestämmelser för konstnärer håller på att utvecklas är det inte säkert att de är tillräckliga.
Fram till dess att domare fattar beslut i enskilda fall, vilket kan ta månader, utsätter sig generativa AI-företag för betydande juridiska risker i många jurisdiktioner.
Historien visar att upphovsrättslagstiftningen kan anpassas till ny teknik, men så länge det inte råder konsensus är både konstnärer och AI-utvecklare i stort sett ovetande.
Domare sätter käppar i hjulet för stämningar
Hittills har domarna inte gett artisterna mycket att vara optimistiska över.
Till exempel har den amerikanska distriktsdomaren William Orrick ifrågasatt Kelly McKernans stämningsansökan.
Enligt domare OrrickMcKernan och de andra kärandena behövde "tillhandahålla mer fakta" om det påstådda upphovsrättsintrånget och tydligt skilja på sina krav mot varje företag (Stability AI, DeviantArt och Midjourney).
Orrick noterade att systemen hade tränats på "fem miljarder komprimerade bilder", så konstnärerna måste lägga fram starkare bevis för att just deras verk var inblandade i det påstådda upphovsrättsintrånget. A webbplats som följer denna stämning har nyligen laddat upp teknisk information om hur dessa modeller fungerar genom att interpolera innehåll från bilder i deras träningsuppsättning.
Målet företräds av advokatbyrån Joseph Saveri advokatbyråsom också företräder minst 5 andra liknande fall mot AI-företag.
Och återigen, upphovsrätten kan eventuellt kränkas vid datainsamling snarare än vid generering.
Avsnitt 1202 (b) i USA: s Digital Millennium Copyright Act "handlar om identiska 'kopior ... av ett verk' - inte om avvikande utdrag och anpassningar" - att argumentera för att verk "kopieras" av AI-modellens process är potentiellt bräckligt.
Orricks synpunkter väcker också frågor om ansvaret för företag som MidJourney och DeviantArt, som införlivar Stable Diffusion-teknik från Stability AI i sina egna generativa AI-system.
IOm AI-utvecklare, som OpenAI, Meta etc., tillskrivs ett visst ansvar för att ha gjort intrång i konstnärers upphovsrätt, är de sårbara för ytterligare rättsliga åtgärder.
Författare och skribenter lanserar också rättstvister
I ett annat ny stämningDen amerikanska komikern och författaren Sarah Silverman och författarna Christopher Golden och Richard Kadrey hävdar att deras ord olagligen har använts för att träna AI-modeller som ChatGPT och LLaMA.
Stämningsansökan innehåller parallella yrkanden till dem som inlämnats av bildkonstnärer, men den här gången tränas AI:erna på offentliga textdata.
I stämningsansökan hävdas att ChatGPT kunde göra korrekta sammanfattningar av böcker som Silvermans "The Bedwetter", Goldens "Ararat" och Kadreys "Sandman Slim". Avgörande är att detaljnivån i sammanfattningarna inte kan förklaras av utdrag ur böckerna som laddats upp på Wikipedia eller bokhandlarnas webbplatser.
Kärandeparterna anklagar OpenAI och Meta för att ha använt upphovsrättsskyddade böcker från "skuggbibliotek" utan samtycke.
Skuggbibliotek, som Bibliotik, Library Genesis och Z-Library, innehåller stora mängder olagligt kopierad information.
Även om det är uppenbart att AI-företag har tjänat pengar på produkter med hjälp av upphovsrättsskyddat arbete, har de flera lager av skydd, inklusive den inneboende komplexa karaktären hos deras modeller och det idiosynkratiska utrymme de upptar i det moraliska, etiska och juridiska landskapet.
Vad har domstolarna att besluta om?
Medan tillsynsmyndigheterna fortfarande överlägger om regler kring AI, kan domare ha den första chansen att forma det framtida upphovsrättslandskapet.
Detta kan resultera i ett lapptäcke av lagstiftning som begränsas av de specifika omständigheterna i varje enskilt fall och den jurisdiktion där det avgjordes.
För närvarande finns det många frågor att besvara, bland annat:
F1: Krävs det licens för att utbilda en modell i upphovsrättsskyddat material?
- Rättvis användning kontra licensiering: Domstolar kan behöva avgöra om tillfällig kopiering av data under utbildning faller inom ramen för "fair use", vilket skulle tillåta användning utan licens. Detta kan bero på faktorer som syftet med kopieringen, arten av det upphovsrättsskyddade verket, mängden och väsentligheten av den del som används och effekten på det upphovsrättsskyddade verkets marknadsvärde.
- Internationella perspektiv: Olika jurisdiktioner kan ha olika ståndpunkter i denna fråga. EU:s direktiv om upphovsrätt kan till exempel tolkas på ett annat sätt än den amerikanska upphovsrättslagen.
F2: Gör generativa AI-utdata intrång i upphovsrätten för det material som modellen tränades på?
- Fastställande av härlett arbete: Är det generativa resultatet bara en omvandling, eller skapar det faktiskt ett härlett verk som gör intrång i upphovsrätten? Denna fråga kan kräva en komplex analys av likhet och kreativitet.
- Ansvarsfrågor: Om det sker ett intrång, vem är då ansvarig? Skaparen av AI:n? Användaren av AI? Distributören?
F3: Bryter generativ AI mot restriktioner för att ta bort, ändra eller förfalska information om hantering av upphovsrätt?
- Särskilda fall: Analys av specifika algoritmer som Stable Diffusion kan vara nödvändig för att avgöra om genererade verk oavsiktligt kan reproducera eller manipulera vattenstämplar eller annan upphovsrättsinformation.
- Avsiktlig överträdelse kontra oavsiktlig överträdelse: Domstolarna kan behöva avgöra om det fanns en avsikt att ta bort eller ändra upphovsrättsinformation eller om det var en oavsiktlig konsekvens av AI:s funktion.
Fråga 4: Kränker det den personens rättigheter att skapa ett verk i stil med någon annan?
- Definition av rätten till publicitet: Rätten till publicitet varierar från jurisdiktion till jurisdiktion. Domstolarna kan behöva tolka om skapandet av verk i någons stil är liktydigt med att använda dennes bild eller identitet.
- Kommersiell kontra icke-kommersiell användning: Tillämpningen kan skilja sig åt beroende på om AI:s resultat används för kommersiell vinning eller inte.
Fråga 5: Hur tillämpas licenser med öppen källkod på träning av AI-modeller och distribution av resultatet?
- Förstå licensiering av öppen källkod: Domstolar kan behöva avgöra hur licenser för öppen källkod ska tillämpas på AI-träningsdata och genererade resultat.
Just nu saknar vi en sak: ett avgörande. Just nu skulle det vara dumt att förutsäga om omotiverad dataskrapning kommer att förbli acceptabel. Om skaparna hittar en spricka i AI-branschens juridiska rustning kan skadan bli betydande. Men det ser ut som ett stort om.
När domarna börjar tränga igenom och vi kommer närmare en reglering som träder i kraft, bör den framtida inriktningen för AI bli tydligare - Tills nästa utmaning, vill säga.



