

En ny studie visar att träning av AI-bildgeneratorer med AI-genererade bilder så småningom leder till en betydande minskning av utskriftskvaliteten.
Baraniuk och hans team visade hur denna problematiska AI-utbildningsslinga påverkar generativa AI, inklusive StyleGAN och diffusionsmodeller. Dessa är bland de modeller som används för AI-bildgeneratorer som Stable Diffusion, DALL-E och MidJourney.
I sina experimenttränade teamet AI:erna på antingen AI-genererade eller verkliga bilder. 70.000 riktiga människoansikten från Flickr.
När varje AI tränades på sina egna AI-genererade bilder började StyleGAN-bildgeneratorns utdata visa förvrängda och vågiga visuella mönster, medan diffusion-bildgeneratorns utdata blev suddigare.
I båda fallen resulterade träning av AI på AI-genererade bilder i en kvalitetsförlust.
En av de studie Richard Baraniuk från Rice University i Texas, varnar för att det kommer att bli ett sluttande plan att använda syntetiska data, antingen medvetet eller omedvetet.
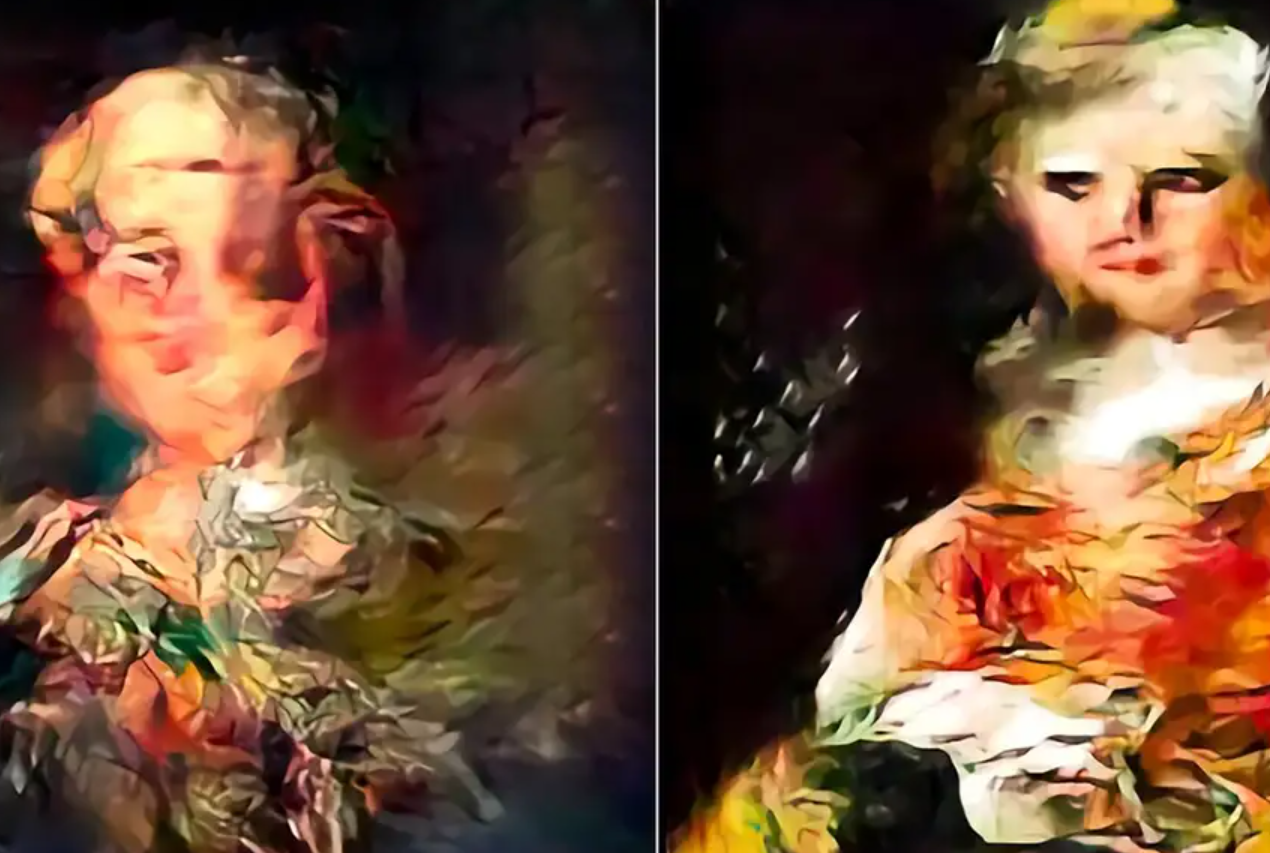
Även om försämringen av bildkvaliteten kunde minskas genom att välja AI-genererade bilder av högre kvalitet för träning, ledde detta till en förlust av mångfalden i bilderna.
Forskarna testade också att införliva en fast uppsättning verkliga bilder i träningsuppsättningar som huvudsakligen innehöll AI-genererade bilder, en metod som ibland används för att komplettera små träningsuppsättningar.
Detta fördröjde dock bara försämringen av bildkvaliteten - det verkar oundvikligt att ju mer AI-genererad data som kommer in i träningsdataset, desto sämre blir resultatet. Det är bara en fråga om när.
Rimliga resultat uppnåddes när varje AI tränades på en blandning av AI-genererade bilder och en ständigt föränderlig uppsättning autentiska bilder. Detta bidrog till att upprätthålla kvaliteten och mångfalden i bilderna.
Det är en utmaning att balansera kvantitet med kvalitet - syntetiska bilder är potentiellt obegränsade jämfört med riktiga bilder, men att använda dem innebär en kostnad.
AI:n börjar få slut på data
AI:er är datahungriga, men autentiska data av hög kvalitet är en begränsad resurs.
Resultaten i denna forskning återspeglar liknande studier för textgenerering, där AI-resultat tenderar att bli lidande när modeller tränas på AI-genererad text.
Forskarna lyfter fram att mindre organisationer med begränsad möjlighet att samla in autentiska data står inför de största utmaningarna när det gäller att filtrera AI-genererade bilder från sina dataset.
Problemet förvärras dessutom av att internet översvämmas av AI-genererat innehåll, vilket gör det otroligt svårt att avgöra vilken typ av data som modellerna tränas på.
Sina Alemohammad, från Rice University, föreslår att man kan utveckla vattenstämplar för att identifiera AI-genererade bilder, men varnar samtidigt för att dolda vattenstämplar som förbises kan försämra kvaliteten på AI-genererade bilder.
Alemohammad avslutar: "Du är förbannad om du gör det och förbannad om du inte gör det. Men det är definitivt bättre att vattenstämpla bilden än att inte göra det."
De långsiktiga konsekvenserna av att AI konsumerar sin produktion är omdiskuterade, men just nu måste AI-utvecklare hitta lösningar för att säkerställa kvaliteten på sina modeller.



