

OpenAI:s chef Sam Altman gav EU en känga och menade att EU:s förslag till AI-lag var överreglerande och omöjligt att uppfylla. Några dagar senare twittrade han att OpenAI är glada över att kunna fortsätta sin verksamhet i EU.
Altman har rest runt i Europa och träffat politiker från Tyskland, Frankrike, Spanien, Polen och Storbritannien. Han ska dock ha ställt in ett möte i Bryssel, där lagstiftarna håller på att utarbeta EU:s AI-lag.
Han hade tidigare sagt att OpenAI skulle kämpa för att följa lagen, "om vi kan följa den så gör vi det, och om vi inte kan det så upphör vi med verksamheten. Vi kommer att försöka. Men det finns tekniska gränser för vad som är möjligt."
Efter en del motreaktioner på sociala medier verkade Altman göra en helomvändning i sina kommentarer: "Vi är glada över att kunna fortsätta att verka här och har naturligtvis inga planer på att flytta."
mycket produktiv vecka med samtal i europa om hur man bäst reglerar AI! vi är glada över att fortsätta att verka här och har naturligtvis inga planer på att lämna.
- Sam Altman (@sama) 26 maj 2023
Altman hade tidigare berättade för Reuters"Det nuvarande utkastet till EU:s AI-lag skulle innebära en överreglering, men vi har hört att det kommer att dras tillbaka."
EU reagerade - den nederländska ledamoten Kim van Sparrentak sade att de lagstiftare som utarbetar AI-lagen "inte ska låta sig utpressas av amerikanska företag".
Hon fortsatte med att säga: "Om OpenAI inte kan uppfylla grundläggande krav på datastyrning, transparens, säkerhet och trygghet, då är deras system inte lämpliga för den europeiska marknaden."
AI-lagen kan placera stora språkmodeller (LLM) i en "högrisk"-kategori
EU:s AI Act definierar olika kategorier av AI, inklusive en kategori med "hög risk" som omfattas av strikta regler för transparens och övervakning. Detta verkar vara kärnan i Altmans farhågor.
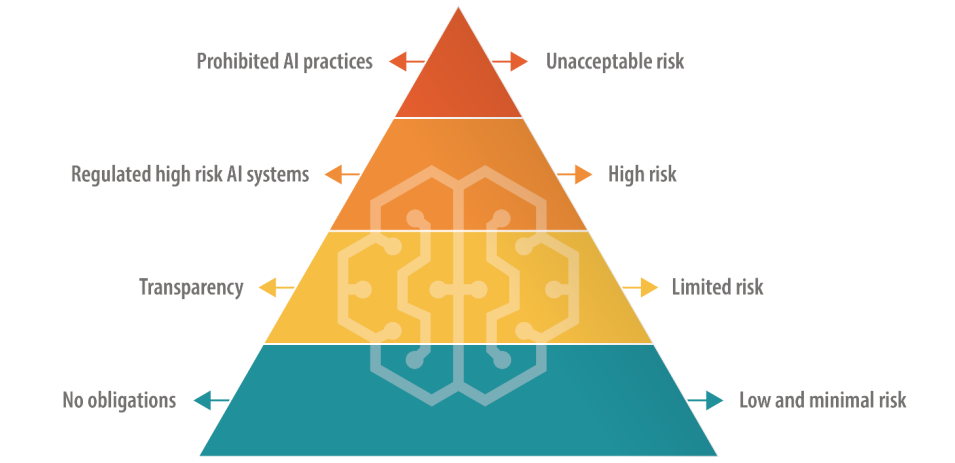
Enligt det nuvarande utkastet måste företag som använder högrisk-AI redovisa allt upphovsrättsskyddat material som ingår i träningsdata och loggaktiviteter för att säkerställa replikerbarhet och spårbarhet av utdata. Det kan bli kostsamt och betungande för mindre AI-företag.
Upphovsrättsskyddat material är fortfarande en knäckfråga
OpenAI är långt ifrån en öppen bok när det gäller upphovsrättsskyddat material i sina utbildningsdata.
Det har visat sig att AI upprepa rader från flera romaner, bland annat Harry Potter och Game of Thrones. Forskare föreslår Detta beror sannolikt på att avsnitt ur böcker ofta är offentligt tillgängliga.
Det finns många pågående upphovsrättsrelaterade rättsfall mot OpenAI, Microsoft och skaparna bakom bildgeneratorer som Midjourney. Just nu vet vi helt enkelt inte i vilken utsträckning AI använder upphovsrättsuppgifter och vilka metoder som används för att hämta dem.
EU vill ändra på detta genom att införa regler för transparens, vilket kan förändra hur AI:er tränas och därmed deras prestanda.
Vi kanske lever i en oreglerad AI-bubbla som är på väg att spricka.



