

Con l'avanzare dell'era dell'IA generativa, un'ampia gamma di aziende si è unita alla mischia e i modelli stessi sono diventati sempre più diversi.
In questo boom dell'IA, molte aziende hanno pubblicizzato i loro modelli come "open source", ma cosa significa davvero nella pratica?
Il concetto di open source affonda le sue radici nella comunità degli sviluppatori di software. Il software open source tradizionale rende il codice sorgente liberamente disponibile a chiunque per la visualizzazione, la modifica e la distribuzione.
In sostanza, l'open-source è un dispositivo di condivisione collaborativa delle conoscenze alimentato dall'innovazione del software, che ha portato a sviluppi come il sistema operativo Linux, il browser web Firefox e il linguaggio di programmazione Python.
Tuttavia, l'applicazione dell'etica open-source agli attuali modelli di intelligenza artificiale di massa è tutt'altro che semplice.
Questi sistemi sono spesso addestrati su vasti set di dati contenenti terabyte o petabyte di dati, utilizzando complesse architetture di reti neurali con miliardi di parametri.
Le risorse informatiche necessarie costano milioni di dollari, i talenti sono scarsi e la proprietà intellettuale è spesso ben protetta.
Lo possiamo osservare in OpenAI, che, come suggerisce il nome, era un laboratorio di ricerca sull'intelligenza artificiale dedicato in gran parte all'etica della ricerca aperta.
Tuttavia, questo etica rapidamente erosa una volta che l'azienda ha sentito l'odore dei soldi e ha avuto bisogno di attrarre investimenti per alimentare i suoi obiettivi.
Perché? Perché i prodotti open-source non sono orientati al profitto e l'intelligenza artificiale è costosa e preziosa.
Tuttavia, con l'esplosione dell'IA generativa, aziende come Mistral, Meta, BLOOM e xAI stanno rilasciando modelli open-source per favorire la ricerca, impedendo al contempo ad aziende come Microsoft e Google di accaparrarsi troppa influenza.
Ma quanti di questi modelli sono veramente open-source, e non solo di nome?
Chiarire quanto siano realmente aperti i modelli open-source
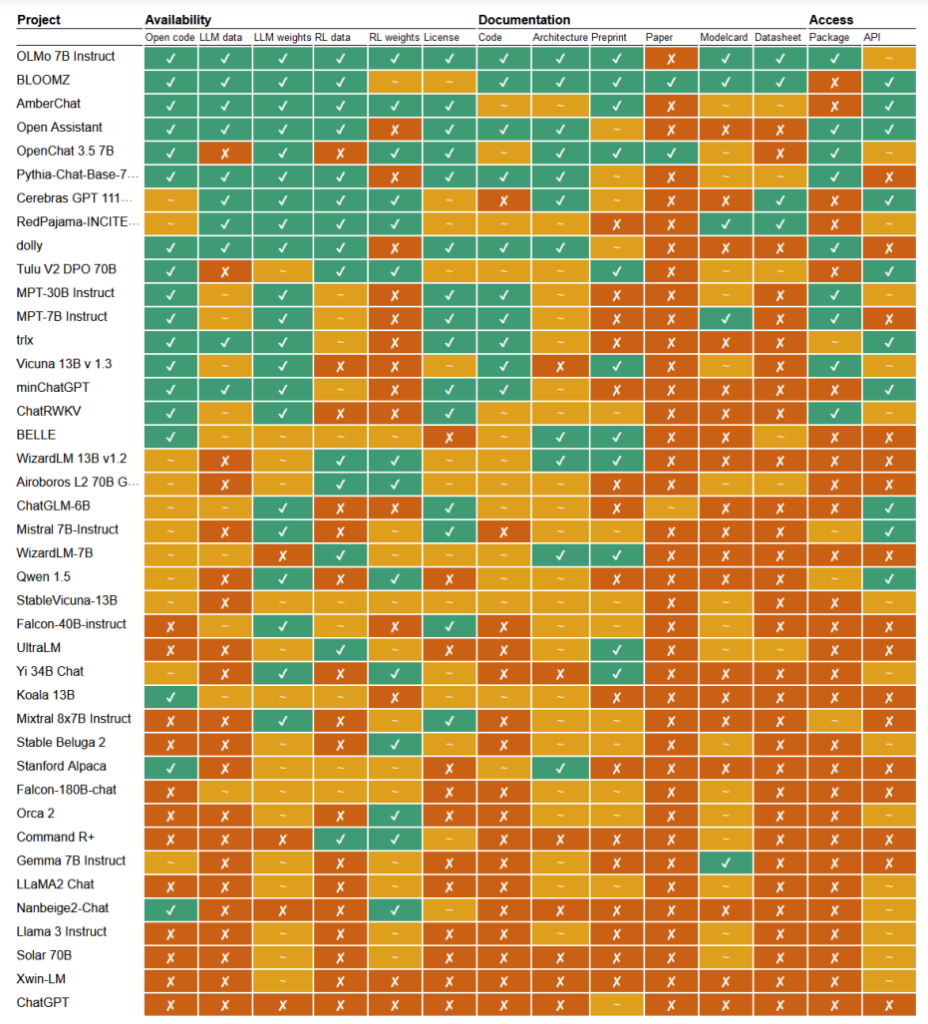
In un recente studio, i ricercatori Mark Dingemanse e Andreas Liesenfeld dell'Università Radboud, nei Paesi Bassi, hanno analizzato numerosi modelli di IA di primo piano per capire quanto siano aperti. Hanno studiato diversi criteri, come la disponibilità di codice sorgente, dati di addestramento, pesi del modello, documenti di ricerca e API.
Ad esempio, il modello LLaMA di Meta e Gemma di Google sono risultati semplicemente "a peso aperto", il che significa che il modello addestrato viene rilasciato pubblicamente per l'uso senza la piena trasparenza del codice, del processo di addestramento, dei dati e dei metodi di messa a punto.
All'altro capo dello spettro, i ricercatori hanno evidenziato BLOOM, un grande modello multilingue sviluppato da una collaborazione di oltre 1.000 ricercatori in tutto il mondo, come un esempio di vera IA open-source. Ogni elemento del modello è liberamente accessibile per l'ispezione e per ulteriori ricerche.
Il documento ha valutato più di 30 modelli (sia di testo che di immagine), ma questi dimostrano l'immensa variazione all'interno di quelli che dichiarano di essere open-source:
- BloomZ (BigScience): Completamente aperto in tutti i criteri, compresi codice, dati di addestramento, pesi del modello, documenti di ricerca e API. Evidenziato come esempio di IA veramente open-source.
- OLMo (Allen Institute for AI): Codice, dati di allenamento, pesi e documenti di ricerca aperti. API solo parzialmente aperta.
- Mistral 7B-Istruzione (Mistral AI): Pesi e API del modello aperti. Codice e documenti di ricerca solo parzialmente aperti. Dati di formazione non disponibili.
- Orca 2 (Microsoft): Pesi del modello e documenti di ricerca parzialmente aperti. Codice, dati di addestramento e API chiusi.
- Istruttore Gemma 7B (Google): Codice e pesi parzialmente aperti. Dati di addestramento, documenti di ricerca e API chiusi. Descritto come "aperto" da Google piuttosto che come "open source".
- Llama 3 Istruttore (Meta): Pesi parzialmente aperti. Codice, dati di allenamento, documenti di ricerca e API chiusi. Un esempio di modello di "pesi aperti" senza una maggiore trasparenza.
Mancanza di trasparenza
La mancanza di trasparenza che circonda i modelli di IA, soprattutto quelli sviluppati dalle grandi aziende tecnologiche, solleva serie preoccupazioni in merito alla responsabilità e alla supervisione.
Senza l'accesso completo al codice del modello, ai dati di addestramento e ad altri componenti chiave, diventa estremamente difficile capire come funzionano questi modelli e prendere decisioni. Ciò rende difficile identificare e risolvere potenziali distorsioni, errori o uso improprio di materiale protetto da copyright.
La violazione del copyright nei dati di addestramento dell'IA è un esempio lampante dei problemi che derivano da questa mancanza di trasparenza. Molti modelli di IA proprietari, come GPT-3.5/4/40/Claude 3/Gemini, sono probabilmente addestrati su materiale protetto da copyright.
Tuttavia, poiché i dati di addestramento sono tenuti sotto chiave, l'identificazione di dati specifici all'interno di questo materiale è quasi impossibile.
Il New York Times recente causa legale contro OpenAI dimostra le conseguenze reali di questa sfida. OpenAI ha accusato il NYT di aver utilizzato attacchi di prompt engineering per esporre i dati di addestramento e indurre ChatGPT a riprodurre i suoi articoli alla lettera, dimostrando così che i dati di addestramento di OpenAI contengono materiale protetto da copyright.
"Il Times ha pagato qualcuno per hackerare i prodotti di OpenAI", ha dichiarato OpenAI.
In risposta, Ian Crosby, il principale consulente legale del NYT, ha dichiarato: "Ciò che OpenAI bizzarramente descrive come 'hacking' è semplicemente l'utilizzo dei prodotti di OpenAI per cercare le prove del furto e della riproduzione di opere protette da copyright del Times. Ed è esattamente quello che abbiamo trovato".
In effetti, questo è solo un esempio di un'enorme quantità di cause legali che sono attualmente bloccate in parte a causa della natura opaca e impenetrabile dei modelli di IA.
Questa è solo la punta dell'iceberg. Senza solide misure di trasparenza e responsabilità, rischiamo un futuro in cui sistemi di IA inspiegabili prendono decisioni che hanno un impatto profondo sulle nostre vite, sull'economia e sulla società, ma restano al riparo da ogni controllo.
Richieste di apertura
Sono stati lanciati appelli ad aziende come Google e OpenAI affinché concedere l'accesso al funzionamento interno dei loro modelli ai fini della valutazione della sicurezza.
Tuttavia, la verità è che nemmeno le aziende di IA capiscono veramente come funzionano i loro modelli.
Si tratta del cosiddetto problema della "scatola nera", che si presenta quando si cerca di interpretare e spiegare le decisioni specifiche del modello in modo comprensibile per l'uomo.
Ad esempio, uno sviluppatore potrebbe sapere che un modello di deep learning è accurato e ha buone prestazioni, ma potrebbe avere difficoltà a individuare esattamente le caratteristiche utilizzate dal modello per prendere le sue decisioni.
Anthropic, che ha sviluppato i modelli Claude, ha recentemente ha condotto un esperimento per identificare il funzionamento di Claude 3 Sonnet, spiegando: "Per lo più trattiamo i modelli di intelligenza artificiale come una scatola nera: qualcosa entra e una risposta esce, e non è chiaro perché il modello abbia dato quella particolare risposta invece di un'altra. Questo rende difficile credere che questi modelli siano sicuri: se non sappiamo come funzionano, come facciamo a sapere che non daranno risposte dannose, distorte, non veritiere o comunque pericolose? Come possiamo fidarci che siano sicuri e affidabili?".
È un'ammissione davvero notevole che il creatore di una tecnologia non comprenda il suo prodotto nell'era dell'intelligenza artificiale.
L'esperimento antropico ha dimostrato che spiegare oggettivamente le produzioni è un compito eccezionalmente difficile. In effetti, Anthropic ha stimato che sarebbe servita più potenza di calcolo per "aprire la scatola nera" che per addestrare il modello stesso!
Gli sviluppatori stanno cercando di combattere attivamente il problema della scatola nera attraverso ricerche come "Explainable AI" (XAI), che mira a sviluppare tecniche e strumenti per rendere i modelli di IA più trasparenti e interpretabili.
I metodi XAI cercano di fornire approfondimenti sul processo decisionale del modello, di evidenziare le caratteristiche più influenti e di generare spiegazioni leggibili dall'uomo. L'XAI è già stato applicato ai modelli utilizzati per le decisioni di applicazioni come lo sviluppo di farmaciin cui la comprensione del funzionamento di un modello potrebbe essere fondamentale per la sicurezza.
Le iniziative open-source sono fondamentali per XAI e per altre ricerche che cercano di penetrare la scatola nera e di fornire trasparenza ai modelli di IA.
Senza l'accesso al codice del modello, ai dati di addestramento e ad altri componenti chiave, i ricercatori non possono sviluppare e testare tecniche per spiegare come funzionano realmente i sistemi di IA e identificare i dati specifici su cui sono stati addestrati.
Le normative potrebbero confondere ulteriormente la situazione dell'open-source
L'Unione Europea Legge sull'AI recentemente approvata si appresta a introdurre nuove norme per i sistemi di IA, con disposizioni che riguardano specificamente i modelli open-source.
Secondo la legge, i modelli generici open-source fino a una certa dimensione saranno esenti da ampi requisiti di trasparenza.
Tuttavia, come sottolineano Dingemanse e Liesenfeld nel loro studio, l'esatta definizione di "IA open source" ai sensi della legge sull'IA non è ancora chiara e potrebbe diventare un punto di scontro.
La legge definisce attualmente i modelli open source come quelli rilasciati con una licenza "libera e aperta" che consente agli utenti di modificare il modello. Tuttavia, non specifica i requisiti per l'accesso ai dati di formazione o ad altri componenti chiave.
Questa ambiguità lascia spazio all'interpretazione e a potenziali pressioni da parte di interessi aziendali. I ricercatori avvertono che il perfezionamento della definizione di open source nella legge sull'IA "costituirà probabilmente un unico punto di pressione che sarà preso di mira dalle lobby aziendali e dalle grandi imprese".
C'è il rischio che, in assenza di criteri chiari e solidi per definire ciò che costituisce un'IA veramente open-source, le norme possano inavvertitamente creare scappatoie o incentivi per le aziende a impegnarsi in un "open-washing", ovvero a dichiarare l'apertura per i vantaggi legali e di pubbliche relazioni, pur mantenendo aspetti importanti dei loro modelli proprietari.
Inoltre, la natura globale dello sviluppo dell'IA implica che normative diverse tra le varie giurisdizioni potrebbero complicare ulteriormente il panorama.
Se i principali produttori di IA, come gli Stati Uniti e la Cina, adottano approcci divergenti ai requisiti di apertura e trasparenza, ciò potrebbe portare a un ecosistema frammentato in cui il grado di apertura varia notevolmente a seconda del luogo di origine di un modello.
Gli autori dello studio sottolineano la necessità che le autorità di regolamentazione si impegnino a stretto contatto con la comunità scientifica e le altre parti interessate per garantire che qualsiasi disposizione sull'open-source contenuta nella legislazione sull'IA sia fondata su una profonda comprensione della tecnologia e dei principi di apertura.
Come concludono Dingemanse e Liesenfeld in una discussione con la NaturaÈ lecito affermare che il termine "open source" assumerà un peso legale senza precedenti nei Paesi disciplinati dall'AI Act dell'UE".
Il modo in cui tutto ciò si concretizzerà avrà implicazioni epocali per la direzione futura della ricerca e della diffusione dell'IA.



