

I ricercatori di Google DeepMind hanno sviluppato NATURAL PLAN, un benchmark per valutare la capacità dei LLM di pianificare attività del mondo reale sulla base di suggerimenti in linguaggio naturale.
La prossima evoluzione dell'IA consiste nel farle uscire dai confini di una piattaforma di chat e farle assumere ruoli agenziali per completare attività su tutte le piattaforme per nostro conto. Ma è più difficile di quanto sembri.
Pianificare attività come la programmazione di una riunione o la compilazione di un itinerario per le vacanze può sembrare semplice per noi. Gli esseri umani sono bravi a ragionare su più fasi e a prevedere se un'azione raggiungerà o meno l'obiettivo desiderato.
Potreste trovarlo facile, ma anche i migliori modelli di intelligenza artificiale fanno fatica a pianificare. Potremmo fare un benchmark per vedere quale LLM è più bravo a pianificare?
Il benchmark NATURAL PLAN mette alla prova i LLM su 3 compiti di pianificazione:
- Pianificazione del viaggio - Pianificare l'itinerario di un viaggio con vincoli di volo e di destinazione
- Pianificazione della riunione - Programmazione di incontri con più amici in luoghi diversi
- Pianificazione del calendario - Programmare le riunioni di lavoro tra più persone in base agli orari esistenti e ai vari vincoli.
L'esperimento è iniziato con un prompt di pochi colpi in cui ai modelli sono stati forniti 5 esempi di prompt e le relative risposte corrette. Poi sono stati sollecitati con richieste di pianificazione di difficoltà variabile.
Ecco un esempio di richiesta e soluzione fornita come esempio ai modelli:

Risultati
I ricercatori hanno testato GPT-3.5, GPT-4, GPT-4o, Gemini 1.5 Flash e Gemini 1,5 Pro, nessuno dei quali si è comportato molto bene in questi test.
I risultati devono essere stati ben accolti nell'ufficio di DeepMind, visto che Gemini 1.5 Pro si è aggiudicato il primo posto.

Come previsto, i risultati peggiorano in modo esponenziale con le richieste più complesse, quando aumenta il numero di persone o di città. Ad esempio, si osservi quanto rapidamente la precisione sia diminuita con l'aggiunta di altre persone al test sulla pianificazione di una riunione.
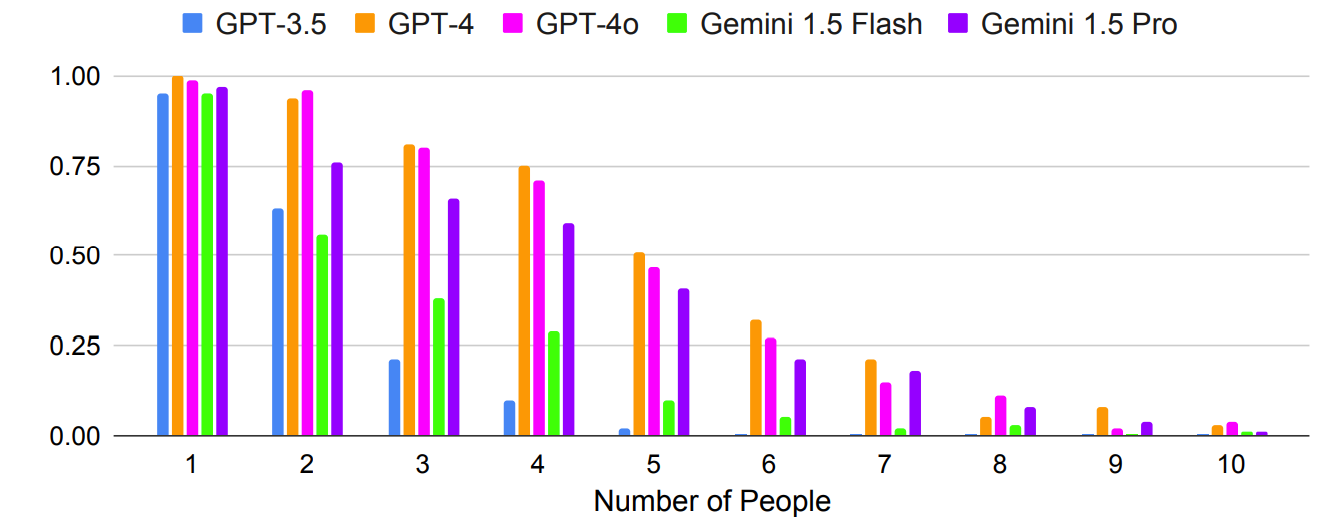
La richiesta di più colpi può migliorare l'accuratezza? I risultati della ricerca indicano che è possibile, ma solo se il modello ha una finestra di contesto sufficientemente ampia.
La finestra di contesto più ampia di Gemini 1.5 Pro consente di sfruttare un maggior numero di esempi in contesto rispetto ai modelli GPT.
I ricercatori hanno scoperto che nella Pianificazione del viaggio, l'aumento del numero di scatti da 1 a 800 migliora la precisione di Gemini Pro 1.5 da 2,7% a 39,9%.
La carta ha osservato: "Questi risultati mostrano la promessa della pianificazione in-context, dove le capacità di long-context consentono ai LLM di sfruttare ulteriori contesti per migliorare la pianificazione".
Un risultato strano è stato che il GPT-4o era davvero pessimo nella pianificazione del viaggio. I ricercatori hanno scoperto che faticava a "comprendere e rispettare i vincoli di connettività dei voli e di data del viaggio".
Un altro risultato strano è che l'autocorrezione ha portato a un calo significativo delle prestazioni dei modelli in tutti i modelli. Quando i modelli sono stati invitati a controllare il loro lavoro e ad apportare correzioni, hanno commesso più errori.
È interessante notare che i modelli più forti, come GPT-4 e Gemini 1.5 Pro, hanno subito perdite maggiori rispetto a GPT-3.5 in fase di autocorrezione.
L'IA agenziale è una prospettiva entusiasmante e stiamo già assistendo ad alcuni casi d'uso pratici in Microsoft Copilot agenti.
Ma i risultati dei test di benchmark NATURAL PLAN dimostrano che c'è ancora molta strada da fare prima che l'intelligenza artificiale possa gestire una pianificazione più complessa.
I ricercatori di DeepMind hanno concluso che "NATURAL PLAN è molto difficile da risolvere per i modelli più avanzati".
Sembra che l'intelligenza artificiale non sostituirà ancora le agenzie di viaggio e gli assistenti personali.



