

Google DeepMind ha rilasciato Gecko, un nuovo benchmark per la valutazione completa dei modelli AI text-to-image (T2I).
Negli ultimi due anni, abbiamo visto generatori di immagini AI come DALL-E e Viaggio intermedio migliorano progressivamente con ogni versione rilasciata.
Tuttavia, decidere quale dei modelli sottostanti utilizzati da queste piattaforme sia il migliore è stato in gran parte soggettivo e difficile da valutare.
Affermare che un modello è "migliore" di un altro non è così semplice. Modelli diversi eccellono in vari aspetti della generazione di immagini. Uno può essere bravo nel rendering del testo, mentre un altro può essere migliore nell'interazione con gli oggetti.
Una sfida fondamentale che i modelli T2I devono affrontare è quella di seguire ogni dettaglio nel prompt e di rifletterlo accuratamente nell'immagine generata.
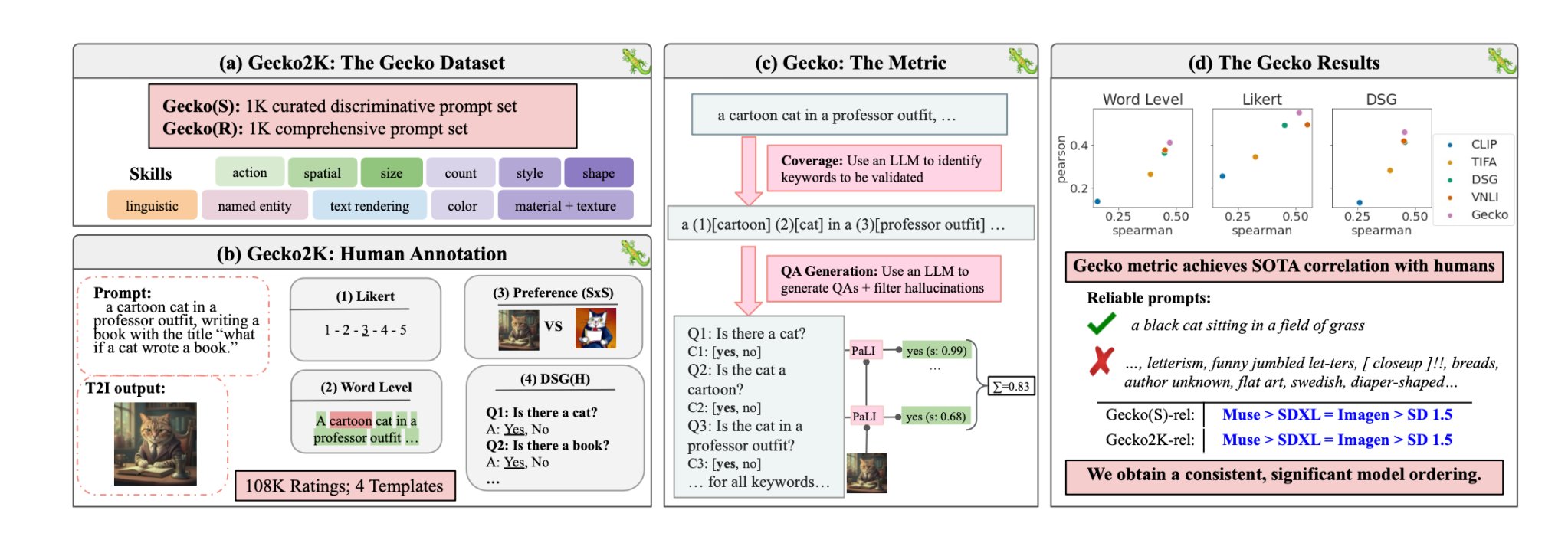
Con Gecko, il DeepMind ricercatori hanno creato un parametro di riferimento che valuta le capacità dei modelli T2I in modo simile a come fanno gli esseri umani.
Set di competenze
I ricercatori hanno innanzitutto definito un insieme completo di competenze rilevanti per la generazione di T2I. Queste includono la comprensione dello spazio, il riconoscimento delle azioni, la resa del testo e altre. Hanno poi suddiviso queste abilità in sotto-abilità più specifiche.
Ad esempio, alla voce rendering del testo, le sottocompetenze possono includere il rendering di diversi font, colori o dimensioni del testo.
Un LLM è stato poi utilizzato per generare prompt per testare la capacità del modello T2I su una specifica abilità o sub-abilità.
Ciò consente ai creatori di un modello T2I di individuare non solo quali competenze sono impegnative, ma anche a quale livello di complessità una competenza diventa impegnativa per il loro modello.
Valutazione umana e automatica
Gecko misura anche la precisione con cui un modello T2I segue tutti i dettagli di una richiesta. Anche in questo caso, è stato utilizzato un LLM per isolare i dettagli chiave di ogni richiesta di input e quindi generare una serie di domande relative a tali dettagli.
Queste domande possono essere sia semplici e dirette sugli elementi visibili nell'immagine (ad esempio, "C'è un gatto nell'immagine?"), sia più complesse che verificano la comprensione della scena o le relazioni tra gli oggetti (ad esempio, "Il gatto è seduto sopra il libro?").
Un modello di Visual Question Answering (VQA) analizza quindi l'immagine generata e risponde alle domande per verificare l'accuratezza con cui il modello T2I allinea l'immagine di output a una richiesta di input.
I ricercatori hanno raccolto oltre 100.000 annotazioni umane in cui i partecipanti assegnavano un punteggio a un'immagine generata in base all'allineamento dell'immagine a criteri specifici.
Agli esseri umani è stato chiesto di considerare un aspetto specifico della richiesta di input e di assegnare un punteggio all'immagine su una scala da 1 a 5, in base a quanto fosse in linea con la richiesta.
Utilizzando le valutazioni annotate dall'uomo come gold standard, i ricercatori hanno potuto confermare che la loro metrica di autovalutazione "è meglio correlata alle valutazioni umane rispetto alle metriche esistenti per il nostro nuovo set di dati".
Il risultato è un sistema di benchmarking in grado di attribuire numeri a fattori specifici che rendono buona o meno un'immagine generata.
Gecko assegna essenzialmente un punteggio all'immagine in uscita in modo molto simile a come noi decidiamo intuitivamente se siamo soddisfatti o meno dell'immagine generata.
Qual è quindi il miglior modello text-to-image?
In la loro cartaI ricercatori hanno concluso che il modello Muse di Google batte Stable Diffusion 1.5 e SDXL nel benchmark Gecko. Forse sono di parte, ma i numeri non mentono.



