Il video di Google che mostrava le capacità del suo nuovo modello Gemini era a dir poco stupefacente. Sfortunatamente, la verità sulla bontà di Gemini e su ciò che è in grado di fare è inferiore al clamore del marketing.
Quando abbiamo visto per la prima volta il video dimostrativo che mostrava Gemini interagire in tempo reale con il presentatore, siamo rimasti a bocca aperta. Eravamo così eccitati che ci sono sfuggite alcune avvertenze fondamentali all'inizio e abbiamo accettato il video al valore nominale.
Il testo nei primi secondi del video dice: "Abbiamo catturato filmati per testarlo su una vasta gamma di sfide, mostrandogli una serie di immagini e chiedendogli di ragionare su ciò che vede".
Quello che è successo realmente dietro le quinte è la causa della Le critiche ricevute da Google e gli interrogativi etici che solleva.
Gemelli non stava guardando un video in diretta del presentatore che disegnava una papera o muoveva delle tazze. E non stava nemmeno rispondendo ai messaggi vocali che si sentivano. Il video era una presentazione di marketing stilizzata di una verità più semplice.
In realtà, a Gemini sono state presentate immagini fisse e messaggi di testo più dettagliati rispetto alle domande che si sentono fare dal presentatore.
Un portavoce di Google ha confermato che le parole che si sentono pronunciare nel video sono "estratti reali dei prompt usati per produrre l'output Gemini che segue".
Quindi, messaggi di testo dettagliati, immagini fisse e risposte di testo. Quello che Google ha dimostrato è una funzionalità che il GPT-4 possiede da mesi.
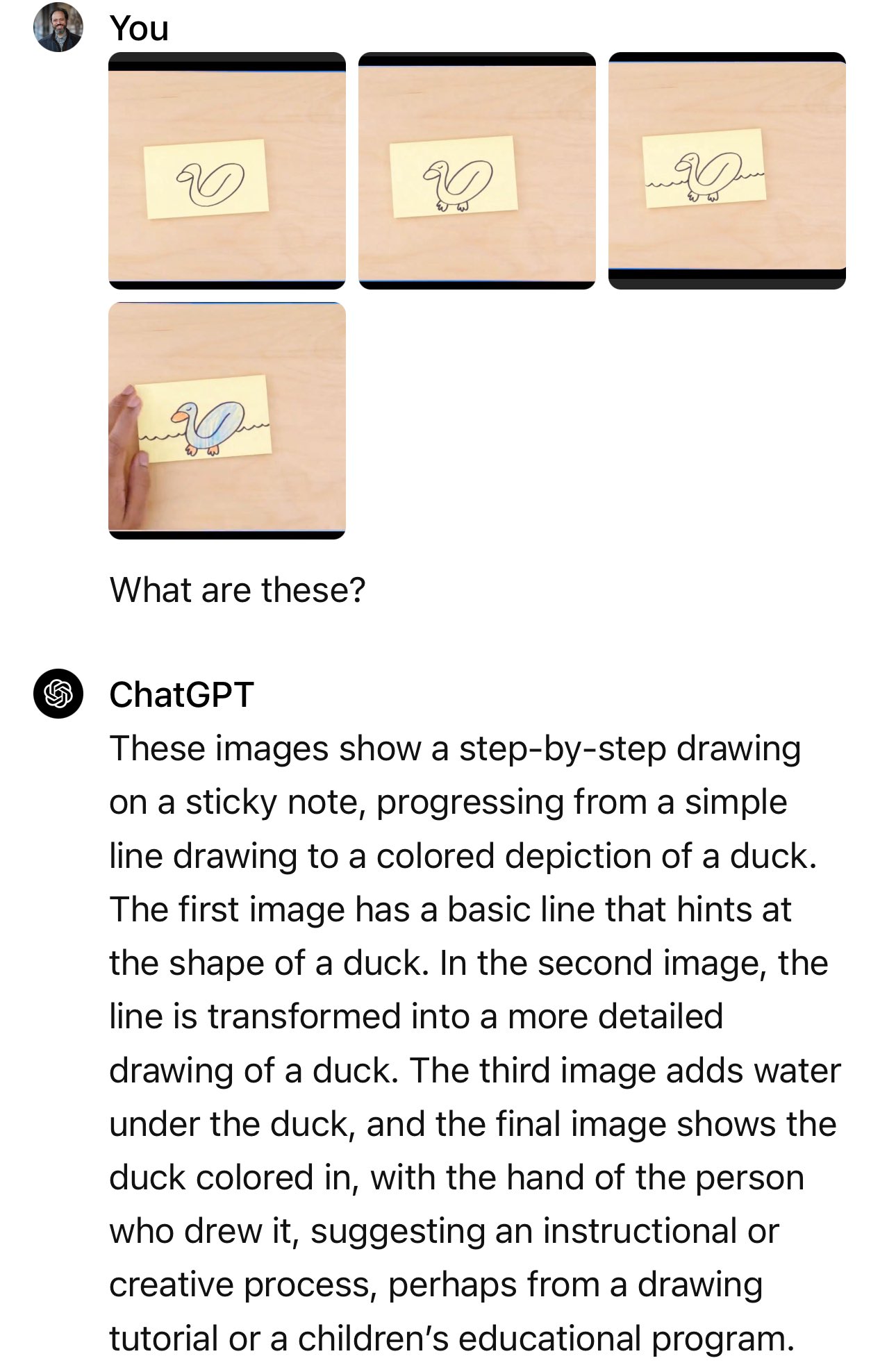
Il post sul blog di Google mostra le immagini fisse e i messaggi di testo effettivamente utilizzati.
Nell'esempio dell'automobile, il presentatore chiede: "In base al loro design, quale di queste andrebbe più veloce?".
La domanda che è stata utilizzata è stata: "Quale di queste auto è più aerodinamica? Quella a sinistra o quella a destra? Spiegate perché, usando dettagli visivi specifici".
E quando si ricrea l'esperimento su Bard, che Gemini ora gestisce, non sempre si riesce a farlo bene.

Volevo davvero credere che Gemini potesse seguire la palla mentre le tre tazze venivano spostate, ma purtroppo nemmeno questo è vero.
Il post sul blog di Google mostra che per la dimostrazione di mescolamento delle tazze sono state necessarie molte richieste e spiegazioni.

È comunque impressionante che un modello AI sia in grado di farlo, ma non è quello che ci è stato venduto nel video.
È così, Google?
Stiamo facendo delle ipotesi, ma molto probabilmente la demo mostrava i risultati ottenuti da Google con Gemini Ultra, che non è ancora stato rilasciato.
Quindi, quando Gemini Ultra verrà rilasciato, sembra che sarà in grado di fare ciò che GPT-4 ha fatto per mesi. Le implicazioni non sono grandi.
Stiamo raggiungendo un limite massimo per quanto riguarda le capacità dell'IA? Perché se le migliori menti dell'IA lavorano a Google, sicuramente saranno loro a guidare l'innovazione all'avanguardia.
Oppure Google non solo è entrata in gara con lentezza, ma ha faticato a tenere il passo con gli altri? I numeri dei benchmark che Google ha mostrato con orgoglio mostrano che il suo modello ancora da rilasciare ha battuto marginalmente il GPT-4 in alcuni test. Come se la caverà contro il GPT-5?
O forse il reparto marketing di Google ha commesso un errore di valutazione con il video, ma Gemini Ultra sarà comunque migliore di quanto pensiamo. Google afferma che Gemini è veramente multimodale e che comprende i video, il che sarà davvero una novità per i LLM.
Non abbiamo ancora visto un LLM dimostrare la capacità di comprensione video, ma quando succederà varrà la pena di entusiasmarsi. Sarà Gemini Ultra o GPT-5 a mostrarcelo per primo?