

Sam Altman, capo di OpenAI, si è scagliato contro l'UE, suggerendo che la bozza di legge sull'IA dell'UE è eccessivamente regolamentata e impossibile da soddisfare. Giorni dopo ha twittato che OpenAI è entusiasta di continuare a operare nell'UE.
Altman ha viaggiato in tutta Europa, incontrando politici di Germania, Francia, Spagna, Polonia e Regno Unito. Tuttavia, secondo quanto riferito, ha cancellato un appuntamento a Bruxelles, dove i legislatori stanno redigendo la legge europea sull'intelligenza artificiale.
In precedenza aveva dichiarato che OpenAI avrebbe lottato per conformarsi alla legge: "Se possiamo conformarci, lo faremo; se non possiamo, cesseremo di operare. Ci proveremo. Ma ci sono limiti tecnici a ciò che è possibile".
Dopo alcune reazioni sui social media, Altman ha fatto marcia indietro sui suoi commenti: "Siamo entusiasti di continuare a operare qui e naturalmente non abbiamo intenzione di andarcene".
Una settimana molto produttiva di conversazioni in Europa su come regolamentare al meglio l'IA! Siamo entusiasti di continuare a operare qui e naturalmente non abbiamo intenzione di andarcene.
- Sam Altman (@sama) 26 maggio 2023
Altman aveva precedentemente ha dichiarato a ReutersL'attuale bozza della legge europea sull'IA sarebbe eccessivamente regolamentata, ma abbiamo sentito che verrà ritirata".
L'UE ha risposto: l'europarlamentare olandese Kim van Sparrentak ha detto che i legislatori che stanno elaborando la legge sull'intelligenza artificiale "non dovrebbero lasciarsi ricattare dalle aziende americane".
Ha poi aggiunto: "Se OpenAI non è in grado di rispettare i requisiti fondamentali di governance, trasparenza, sicurezza e protezione dei dati, allora i suoi sistemi non sono adatti al mercato europeo".
L'AI Act potrebbe inserire i modelli linguistici di grandi dimensioni (LLM) in una categoria "ad alto rischio".
La legge europea sull'IA definisce diverse categorie di IA, tra cui una categoria "ad alto rischio" soggetta a regole severe in materia di trasparenza e monitoraggio. Questo sembra essere il centro dei timori di Altman.
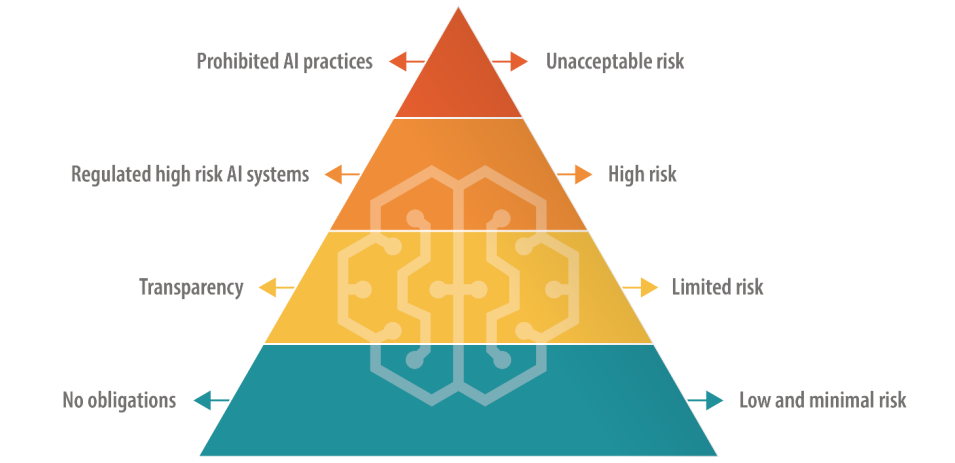
Nella bozza attuale, le aziende che impiegano IA ad alto rischio devono divulgare qualsiasi materiale protetto da copyright incluso nei dati di addestramento e nelle attività di log per garantire la replicabilità e la tracciabilità dei risultati. Potrebbe essere costoso e oneroso per le aziende di IA più piccole.
Il materiale protetto da copyright rimane un punto critico
OpenAI è tutt'altro che un libro aperto per quanto riguarda il materiale protetto da copyright nei suoi dati di addestramento.
È stato riscontrato che l'IA ripetere le linee da diversi romanzi, tra cui Harry Potter e Game of Thrones. I ricercatori suggeriscono Questo è probabilmente dovuto al fatto che i brani dei libri sono spesso di dominio pubblico.
Ci sono molti cause legali pendenti relative al diritto d'autore contro OpenAI, Microsoft e i creatori di generatori di immagini come Viaggio intermedio. Al momento non conosciamo l'entità dell'utilizzo da parte dell'IA dei dati sul copyright e i metodi per recuperarli.
L'UE vuole cambiare questa situazione introducendo regole di trasparenza che potrebbero modificare le modalità di addestramento delle IA e, di conseguenza, le loro prestazioni.
Forse viviamo in una bolla di intelligenza artificiale non regolamentata che sta per scoppiare.



