

El fundador y consejero delegado de HyperWrite, Matt Shumer, ha anunciado que su nuevo modelo, Reflection 70B, utiliza un sencillo truco para resolver las alucinaciones de LLM y ofrece unos impresionantes resultados de benchmark que superan a modelos más grandes e incluso cerrados como GPT-4o.
Shumer colaboró con Glaive, proveedor de datos sintéticos, para crear el nuevo modelo, basado en el modelo Llama 3.1-70B Instruct de Meta.
En el anuncio de lanzamiento en Hugging Face, Shumer dijo. "Reflection Llama-3.1 70B es (actualmente) el mejor LLM de código abierto del mundo, entrenado con una nueva técnica llamada Reflection-Tuning que enseña a un LLM a detectar errores en su razonamiento y corregir el rumbo".
Si Shumer encontrara una forma de resolver el problema de las alucinaciones de la IA, sería increíble. Los puntos de referencia que compartió parecen indicar que el Reflection 70B está muy por delante de otros modelos.
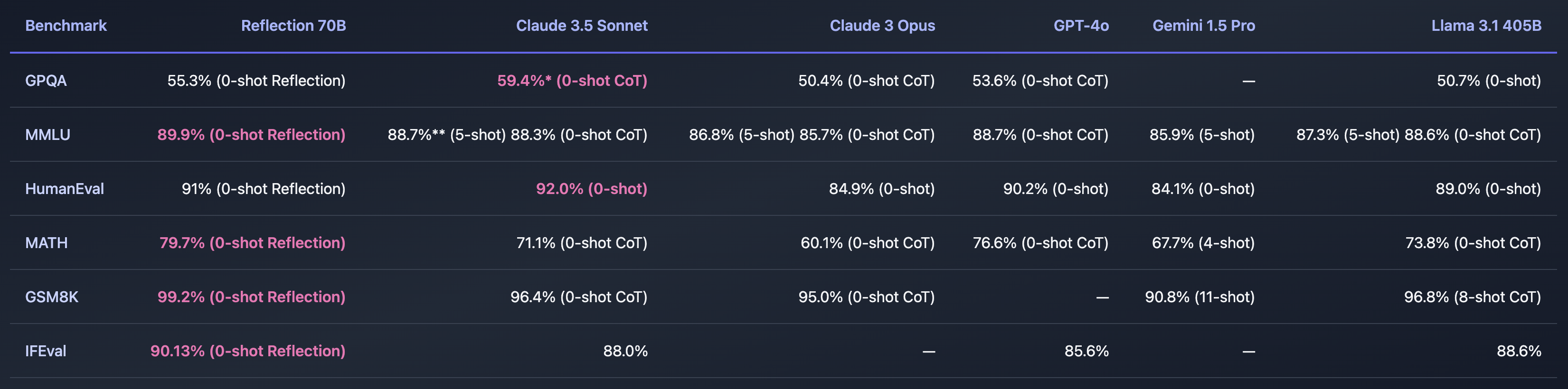
El nombre del modelo hace referencia a su capacidad de autocorrección durante la inferencia. Shumer no da demasiados detalles, pero explica que el modelo reflexiona sobre su respuesta inicial a una pregunta y sólo la emite cuando está convencido de que es correcta.
Shumer afirma que se está trabajando en una versión 405B de Reflection que dejará boquiabiertos a otros modelos, incluido el GPT-4o, cuando se presente la semana que viene.
¿Es Reflection 70B una estafa?
¿Es demasiado bueno para ser verdad? Reflection 70B puede descargarse en Huging Face, pero los primeros usuarios no fueron capaces de duplicar el impresionante rendimiento que mostraban los puntos de referencia de Shumer.
En Parque infantil de reflexión te permite probar el modelo, pero dice que, debido a la gran demanda, la demo está temporalmente inactiva. Las sugerencias "Contar 'r' en fresa" y "9,11 frente a 9,9" indican que el modelo responde correctamente a estas preguntas difíciles. Pero algunos usuarios afirman que Reflection se ha ajustado específicamente para responder a estas preguntas.
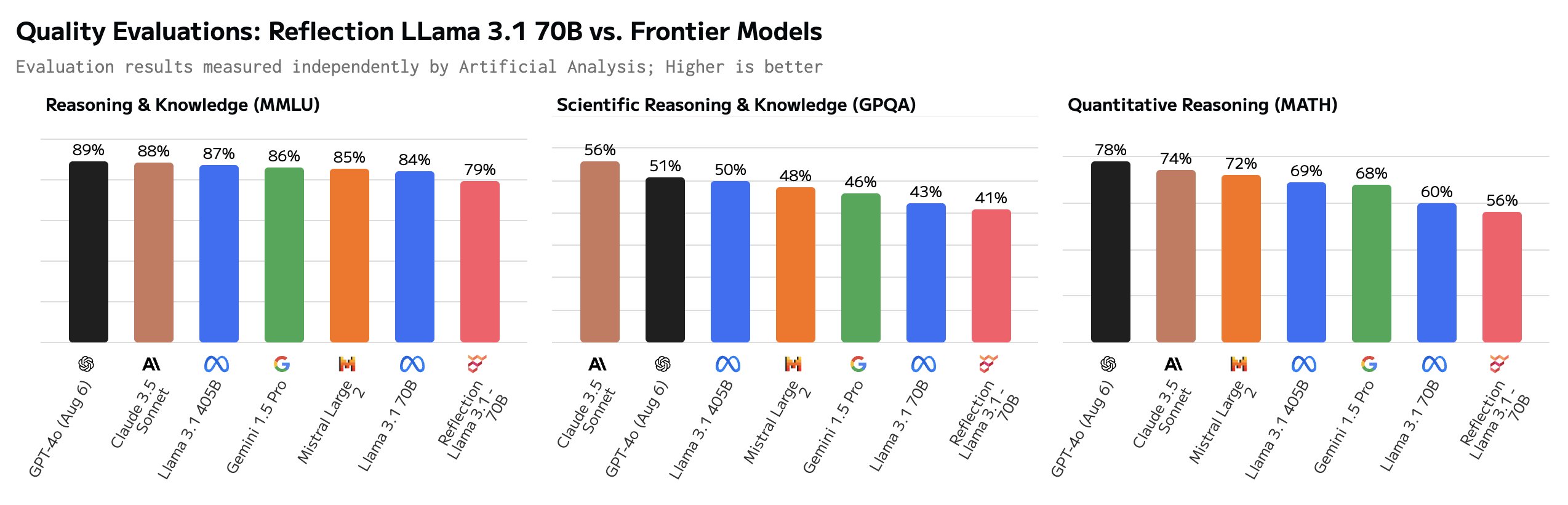
Algunos usuarios cuestionaron los impresionantes valores de referencia. El GSM8K de más de 99% parecía especialmente sospechoso.
¡Hola Matt! Esto es super interesante, pero estoy bastante sorprendido de ver una puntuación GSM8k de más de 99%. Según tengo entendido, es probable que más de 1% de GSM8k estén mal etiquetados (¡la respuesta correcta es en realidad incorrecta)!
- Hugh Zhang (@hughbzhang) 5 de septiembre de 2024
Algunas de las respuestas verdaderas del conjunto de datos GSM8K son en realidad incorrectas. En otras palabras, la única forma de superar la puntuación de 99% en el GSM8K era proporcionar las mismas respuestas incorrectas a esos problemas.
Después de algunas pruebas, los usuarios dicen que Reflection es en realidad peor que Llama 3.1 y que en realidad era sólo Llama 3 con el ajuste LoRA aplicado.
En respuesta a los comentarios negativos, Shumer publicó una explicación en X diciendo: "Actualización rápida - hemos vuelto a cargar los pesos, pero todavía hay un problema. Acabamos de empezar a entrenar de nuevo para eliminar cualquier posible problema. Debería estar listo pronto".
Shumer explicó que había un fallo con la API y que estaban trabajando en ello. Mientras tanto, proporcionó acceso a una API secreta y privada para que los dudosos pudieran probar Reflection mientras trabajaban en la solución.
Y aquí es donde las ruedas parecen salirse, ya que algunas preguntas cuidadosas parecen mostrar que la API es en realidad sólo una envoltura de Claude 3.5 Sonnet.
"Reflection API" es un wrapper de sonnet 3.5 con prompt. Y actualmente lo disfrazan filtrando la cadena 'claude'.https://t.co/c4Oj8Y3Ol1 https://t.co/k0ECeo9a4i pic.twitter.com/jTm2Q85Q7b
- Joseph (@RealJosephus) 8 de septiembre de 2024
Según los informes, las pruebas posteriores hicieron que la API devolviera resultados de Llama y GPT-4o. Shumer insiste en que los resultados originales son exactos y que están trabajando para corregir el modelo descargable.
¿Se han precipitado los escépticos al llamar estafador a Shumer? Puede que el lanzamiento se haya gestionado mal y que Reflection 70B sea realmente un modelo innovador de código abierto. O tal vez sea otro ejemplo del bombo publicitario de la IA para captar capital de riesgo de inversores que buscan la próxima gran novedad en IA.
Tendremos que esperar uno o dos días para ver cómo evoluciona esto.



