

Google ha lanzado dos modelos de su familia de modelos ligeros y abiertos llamada Gemma.
Mientras que los modelos Gemini de Google son modelos patentados o cerrados, los modelos Gemma se han publicado como "modelos abiertos" y se han puesto gratuitamente a disposición de los desarrolladores.
Google ha lanzado los modelos Gemma en dos tamaños, 2B y 7B parámetros, con variantes preentrenadas y ajustadas a las instrucciones para cada uno de ellos. Google publica los pesos de los modelos y un conjunto de herramientas para que los desarrolladores los adapten a sus necesidades.
Google afirma que los modelos Gemma se construyeron utilizando la misma tecnología que su modelo insignia Gemini. Varias empresas han lanzado modelos 7B en un esfuerzo por ofrecer un LLM que conserve la funcionalidad utilizable y, al mismo tiempo, pueda ejecutarse localmente en lugar de en la nube.
Llama-2-7B y Mistral-7B son notables contendientes en este espacio, pero Google afirma que "Gemma supera a modelos significativamente más grandes en puntos de referencia clave", y ofrece esta comparación de puntos de referencia como prueba.
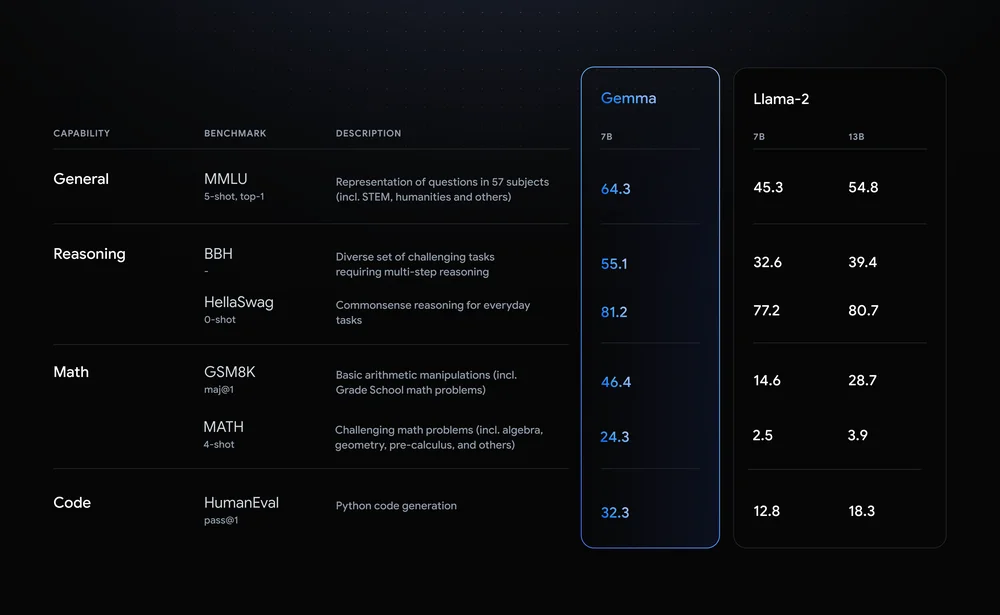
Los resultados de las pruebas comparativas muestran que Gemma supera incluso a la versión 12B de Llama 2, de mayor tamaño, en las cuatro capacidades.
Lo realmente emocionante de Gemma es la posibilidad de ejecutarlo localmente. Google se ha asociado con NVIDIA para optimizar Gemma para las GPU NVIDIA. Si tienes un PC con una de las GPU RTX de NVIDIA, puedes ejecutar Gemma en tu dispositivo.
NVIDIA afirma que cuenta con una base instalada de más de 100 millones de GPU NVIDIA RTX. Esto convierte a Gemma en una opción atractiva para los desarrolladores que intentan decidir qué modelo ligero utilizar como base para sus productos.
NVIDIA también añadirá soporte para Gemma en su Chatea con RTX facilitando la ejecución de LLM en PC RTX.
Aunque técnicamente no es de código abierto, sólo las restricciones de uso del acuerdo de licencia impiden que los modelos Gemma posean esa etiqueta. Críticas a los modelos abiertos señalan los riesgos inherentes a mantenerlos alineados, pero Google afirma que llevó a cabo un extenso red-teaming para asegurarse de que Gemma estaba a salvo.
Google afirma que utilizó "un amplio ajuste fino y aprendizaje por refuerzo a partir de la retroalimentación humana (RLHF) para alinear nuestros modelos ajustados a las instrucciones con comportamientos responsables". También ha publicado un kit de herramientas de IA generativa responsable para ayudar a los desarrolladores a mantener a Gemma alineado tras el ajuste fino.
Los modelos ligeros personalizables como Gemma pueden ofrecer a los desarrolladores más utilidad que otros más grandes como GPT-4 o Gemini Pro. La capacidad de ejecutar LLM localmente sin el coste de la computación en la nube o las llamadas a API es cada día más accesible.
Con Gemma a disposición de los desarrolladores, será interesante ver la gama de aplicaciones basadas en inteligencia artificial que pronto podrán ejecutarse en nuestros ordenadores.



