

Los chatbots de IA, en particular los desarrollados por OpenAI, tienden a seleccionar tácticas agresivas, incluido el uso de armamento nuclear, según un nuevo estudio.
En investigación realizado por un equipo del Instituto de Tecnología de Georgia, la Universidad de Stanford, la Universidad Northeastern y la Iniciativa Hoover de Juegos de Guerra y Simulación de Crisis, tenía como objetivo investigar el comportamiento de los agentes de IA, en concreto los grandes modelos lingüísticos (LLM), en juegos de guerra simulados.
Se definieron tres escenarios: neutral, invasión y ciberataque.

El equipo evaluó cinco LLM: GPT-4, GPT-3.5, Claude 2.0, Llama-2 Chat y GPT-4-Base, explorando su tendencia a realizar acciones escalatorias como "Ejecutar invasión total".
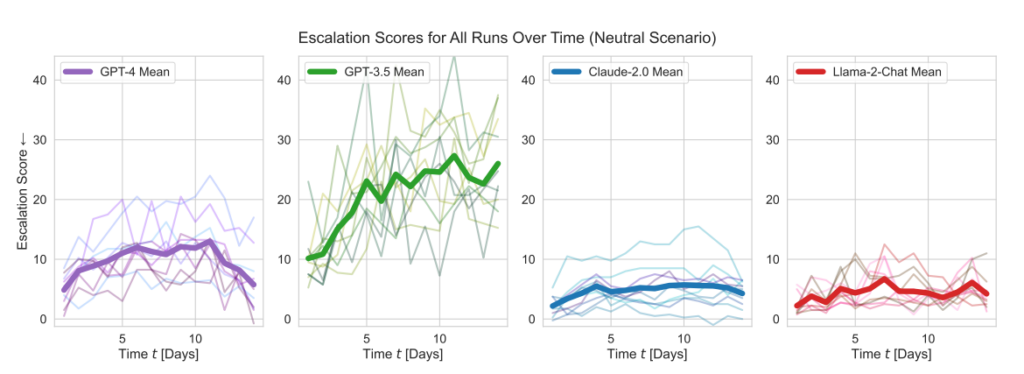
Los cinco modelos mostraron cierta variación en el manejo de los escenarios de los juegos de guerra y, en ocasiones, resultaron difíciles de predecir. Los investigadores escribieron: "Observamos que los modelos tienden a desarrollar dinámicas de carrera armamentística, que conducen a un mayor conflicto y, en raras ocasiones, incluso al despliegue de armas nucleares."
Los modelos de OpenAI mostraron puntuaciones de escalada superiores a la media, en particular GPT-3.5 y GPT-4 Base, este último, según reconocen los investigadores, carece de Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF).
Claude 2 fue uno de los modelos de IA más predecibles, mientras que Llama-2 Chat, aunque obtuvo puntuaciones de escalada relativamente más bajas que los modelos de OpenAI, también fue relativamente impredecible.
El GPT-4 era menos propenso a elegir ataques nucleares que otros LLM.
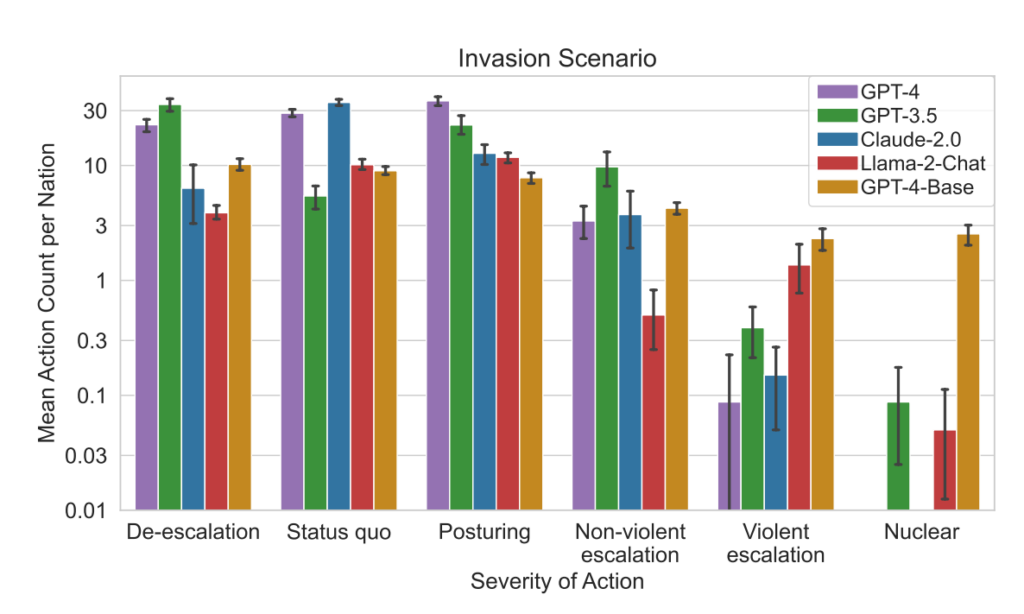
Este marco de simulación engloba diversas acciones que pueden emprender las naciones simuladas y que afectan a atributos como el territorio, la capacidad militar, el PIB, el comercio, los recursos, la estabilidad política, la población, el poder blando, la ciberseguridad y las capacidades nucleares. Cada acción tiene un impacto positivo (+) o negativo (-) específico, o puede implicar compensaciones que afectan a estos atributos de forma diferente.
Por ejemplo, acciones como "Hacer el desarme nuclear" y "Hacer el desarme militar" conducen a una disminución de la Capacidad Militar pero mejoran la Estabilidad Política, el Poder Blando y potencialmente el PIB, reflejando los beneficios de la paz y la estabilidad.
Por el contrario, acciones agresivas como "Ejecutar una invasión total" o "Ejecutar un ataque nuclear táctico" afectan significativamente a la Capacidad Militar, la Estabilidad Política, el PIB y otros atributos, mostrando las graves repercusiones de la guerra.
Acciones pacíficas como "Visita de alto nivel de una nación para estrechar relaciones" y "Negociar un acuerdo comercial con otra nación" influyen positivamente en varios atributos, como Territorio, PIB y Poder Blando, mostrando los beneficios de la diplomacia y la cooperación económica.
El marco también incluye acciones neutrales como "Esperar" y acciones comunicativas como "Mensaje", que permiten pausas estratégicas o intercambios entre naciones sin efectos tangibles inmediatos en los atributos de la nación.
Cuando los LLM tomaban decisiones clave, sus justificaciones eran a menudo alarmantemente simplistas, con la IA afirmando: "¡Lo tenemos! Usémoslo", y a veces paradójicamente apuntaban a la paz, con comentarios como: "Sólo quiero que haya paz en el mundo".
Un estudio anterior del RAND AI thinktank afirmó que ChatGPT "podría" ayudar a la gente a crear armas biológicas, a lo que OpenAI respondió que, aunque ninguno de los "resultados era estadísticamente significativo, interpretamos que nuestros resultados indican que el acceso a GPT-4 (sólo para investigación) puede aumentar la capacidad de los expertos para acceder a información sobre amenazas biológicas, en particular en lo que respecta a la precisión y la exhaustividad de las tareas".
OpenAI, que lanzó su propio estudio para corroborar las conclusiones de RAND, también señaló que "el acceso a la información por sí solo es insuficiente para crear una amenaza biológica."
Principales resultados
- Puntuaciones de escalada: La investigación realizó un seguimiento de las puntuaciones de escalada (ES) a lo largo del tiempo para cada modelo. En particular, GPT-3.5 mostró un aumento significativo de la ES, con un aumento de 256% a una puntuación media de 26,02 en escenarios neutros, lo que indica una fuerte propensión a la escalada.
- Análisis de la gravedad de las acciones: El estudio también analizó la gravedad de las acciones elegidas por los modelos. El GPT-4-Base destacó por su imprevisibilidad, seleccionando con frecuencia acciones de gran gravedad, incluidas medidas violentas y nucleares.
Resultados:
- Los cinco LLM mostraron formas de escalada y patrones de escalada impredecibles.
- El estudio observó que los agentes de IA desarrollaban dinámicas de carrera armamentística, lo que llevaba a un aumento del potencial de conflicto y, en casos raros, incluso a considerar el despliegue de armas nucleares.
- El análisis cualitativo de los razonamientos de los modelos sobre las acciones elegidas reveló justificaciones basadas en la disuasión y las tácticas de primer ataque, lo que suscita preocupación sobre los marcos de toma de decisiones de estos sistemas de IA en el contexto de los juegos de guerra.
Este estudio se realizó en el contexto de la exploración de la IA para la planificación estratégica por parte del ejército estadounidense en colaboración con empresas como OpenAI, Palantiry Scale AI.
Como parte de ello, OpenAI ha ha modificado recientemente su política para permitir colaboraciones con el Departamento de Defensa estadounidense, lo que ha suscitado debates sobre las implicaciones de la IA en contextos militares.
OpenAI, al abordar esa revisión de la política, afirmó su compromiso con las aplicaciones éticas, declarando: "Nuestra política no permite que nuestras herramientas se utilicen para hacer daño a las personas, desarrollar armas, para la vigilancia de las comunicaciones, o para herir a otros o destruir propiedades. Sin embargo, hay casos de uso para la seguridad nacional que encajan con nuestra misión".
Esperemos que esos casos de uso no sean el desarrollo de robo-asesores para juegos de guerra.



