

Nvidia ha anunciado un nuevo software de código abierto que, según afirma, mejorará el rendimiento de inferencia de sus GPU H100.
Gran parte de la demanda actual de GPU de Nvidia se destina a crear potencia de cálculo para entrenar nuevos modelos. Pero una vez entrenados, esos modelos necesitan ser utilizados. La inferencia en IA se refiere a la capacidad de un LLM como ChatGPT para extraer conclusiones o realizar predicciones a partir de los datos con los que se ha entrenado y generar resultados.
Cuando intentas utilizar ChatGPT y aparece un mensaje que te dice que sus servidores se están sobrecargando, es porque el hardware informático está luchando por mantener el ritmo de la demanda de inferencia.
Nvidia afirma que su nuevo software, TensorRT-LLM, puede hacer que su hardware actual funcione mucho más rápido y con mayor eficiencia energética.
El software incluye versiones optimizadas de los modelos más populares, como Meta Llama 2, OpenAI GPT-2 y GPT-3, Falcon, Mosaic MPT y BLOOM.
Utiliza algunas técnicas inteligentes, como una agrupación más eficaz de las tareas de inferencia y técnicas de cuantificación para aumentar el rendimiento.
Los LLM suelen utilizar valores de coma flotante de 16 bits para representar pesos y activaciones. La cuantización toma esos valores y los reduce a valores de coma flotante de 8 bits durante la inferencia. La mayoría de los modelos consiguen mantener su exactitud con esta precisión reducida.
Las empresas que dispongan de infraestructura de cálculo basada en las GPU H100 de Nvidia pueden esperar una enorme mejora del rendimiento de inferencia sin tener que gastar un céntimo utilizando TensorRT-LLM.
Nvidia utilizó un ejemplo de ejecución de un pequeño modelo de código abierto, GPT-J 6, para resumir artículos en el conjunto de datos CNN/Daily Mail. Su antiguo chip A100 se utiliza como velocidad de referencia y luego se compara con el H100 sin TensorRT-LLM y después con él.
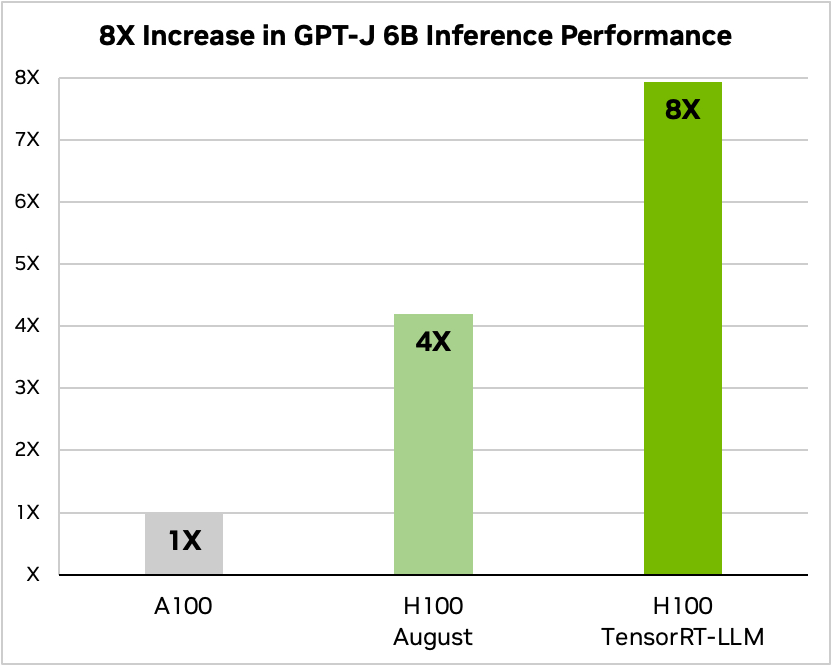
Fuente: Nvidia
Y aquí hay una comparación cuando se ejecuta Meta's Llama 2
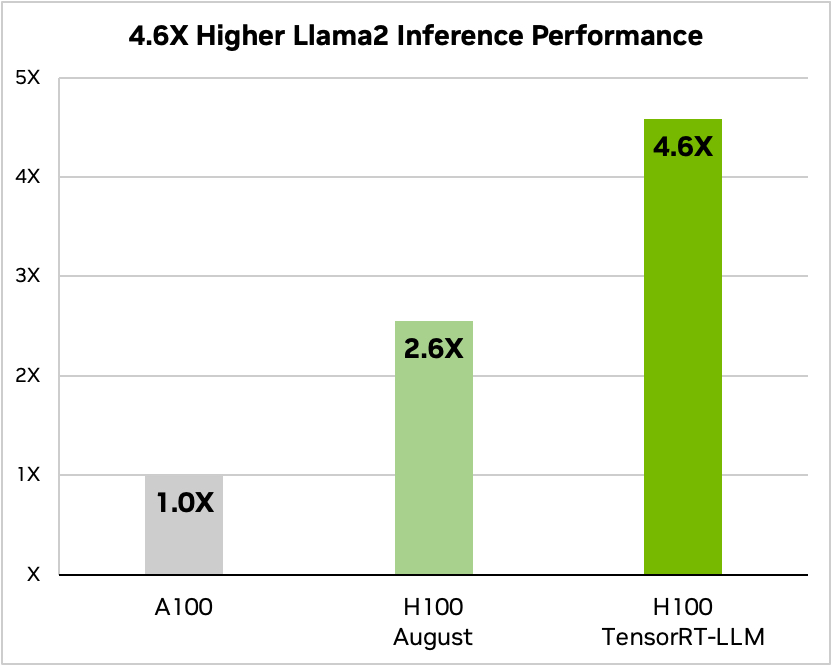
Fuente: Nvidia
Nvidia afirma que sus pruebas han demostrado que, dependiendo del modelo, un H100 que ejecuta TensorRT-LLM consume entre 3,2 y 5,6 veces menos energía que un A100 durante la inferencia.
Si está ejecutando modelos de IA en hardware H100, esto significa que no sólo su rendimiento de inferencia va a ser casi el doble, sino que su factura de energía va a ser mucho menor una vez que instale este software.
TensorRT-LLM también estará disponible para la plataforma Superchips Grace Hopper pero la empresa no ha publicado cifras de rendimiento de la GH200 con su nuevo software.
El nuevo software aún no estaba listo cuando Nvidia sometió a su GH200 Superchip a las pruebas de rendimiento de IA MLPerf, estándares del sector. Los resultados mostraron que el GH200 rendía hasta 17% mejor que un H100 SXM de un solo chip.
Si Nvidia consigue incluso un modesto aumento del rendimiento de inferencia utilizando TensorRT-LLM con el GH200, pondrá a la compañía muy por delante de sus rivales más cercanos. Ser representante de ventas de Nvidia debe de ser el trabajo más fácil del mundo en estos momentos.



