
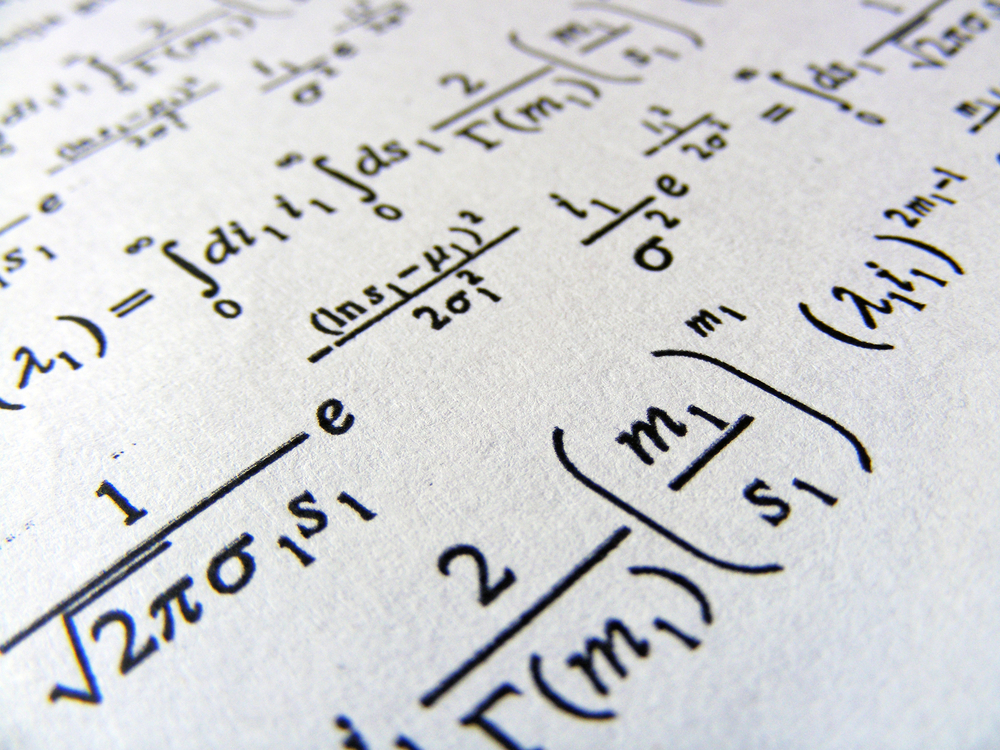
Meta ha desarrollado un nuevo modelo de IA llamado Nougat que puede convertir de forma fiable textos científicos en textos legibles por máquinas.
Si alguna vez ha intentado leer un artículo de investigación científica, empezará a entender por qué es difícil procesarlo electrónicamente. Las herramientas actuales de reconocimiento óptico de caracteres (OCR) analizan el texto línea por línea.
Eso está bien para los documentos puramente textuales, pero los artículos científicos añaden un nivel de complejidad que estas herramientas estándar no pueden tratar.
Los documentos científicos incluyen símbolos y fórmulas matemáticas y científicas que a menudo se añaden como subíndices o superíndices. Incluso los mejores OCR tienen problemas para capturarlos correctamente.
Lo que lo hace aún más difícil es que muchos de estos documentos de investigación están mal escaneados y los originales ya no están disponibles. Nougat, acrónimo de Neural Optical Understanding for Academic Documents, está preparado para el reto.
En lugar de escanear línea por línea, Nougat procesa toda la página utilizando una variante de Vision Transformer de Meta para el análisis de imágenes. El modelo se entrenó con un conjunto de datos de artículos publicados en PubMed Central y arXiv que tenían su correspondiente código fuente LaTeX.
LaTeX es un programa informático que se utiliza para escribir artículos científicos que requieren fórmulas complejas y símbolos matemáticos. El modelo se entrenó observando la imagen del artículo y comparándola con el código que generaba el texto complejo.
He aquí un ejemplo de uno de los experimentos de Meta con la digitalización de un antiguo trabajo de investigación.

Fuente: Meta
Hay algunos ejemplos más impresionantes en la Página de investigación en Facebook.
Nougat no es perfecto, pero aun así logró una puntuación BLEU de más de 91% y una precisión de más de 96% con texto continuo. La puntuación BLEU mide la similitud del texto traducido por la máquina con un conjunto de traducciones de referencia de alta calidad.
En el caso de las fórmulas y tablas, le fue un poco peor, con una precisión de poco más de 75%. Aun así, es mucho mejor que modelos de la competencia como GROBID, que solo acierta el 11% de las veces.
Hay millones de páginas de investigación que no se pueden indexar ni buscar porque sólo pueden ser leídas por humanos. Nougat cambia esta situación al permitir que incluso los PDF de investigación mal escaneados se conviertan en texto legible por máquinas.
Como con tantas otras de sus nuevas herramientas, Meta ha hecho que ésta sea de libre acceso. disponible en GitHub. Sin embargo, puede haber cierto grado de interés propio en este desarrollo. Una vez que los artículos de investigación antiguos son legibles por máquina, pueden utilizarse para entrenar otros modelos de inteligencia artificial.
Será interesante ver qué gemas de investigación perdidas hace tiempo se redescubren usando Nougat.



