

El jefe de OpenAI, Sam Altman, arremetió contra la UE, sugiriendo que el proyecto de Ley de Inteligencia Artificial de la UE era excesivamente regulador e imposible de satisfacer. Días después, tuiteó que a OpenAI le entusiasmaba la idea de seguir operando en la UE.
Altman ha viajado por Europa y se ha reunido con políticos de Alemania, Francia, España, Polonia y Reino Unido. Sin embargo, al parecer canceló una cita en Bruselas, donde los legisladores están redactando la Ley de Inteligencia Artificial de la UE.
Anteriormente había declarado que OpenAI lucharía por cumplir la Ley, "si podemos cumplirla, lo haremos, y si no podemos, dejaremos de operar. Lo intentaremos. Pero hay límites técnicos a lo que es posible".
Tras algunas reacciones en las redes sociales, Altman pareció dar marcha atrás en sus comentarios: "estamos encantados de seguir operando aquí y, por supuesto, no tenemos planes de irnos".
semana muy productiva de conversaciones en europa sobre la mejor manera de regular la IA. estamos encantados de seguir operando aquí y, por supuesto, no tenemos planes de marcharnos.
- Sam Altman (@sama) 26 de mayo de 2023
Altman ya había a ReutersEl actual borrador de la Ley de Inteligencia Artificial de la UE sería excesivamente regulador, pero hemos oído que se va a retirar".
La UE respondió: el eurodiputado holandés Kim van Sparrentak dijo que los legisladores que redactan la Ley de IA "no deberían dejarse chantajear por las empresas estadounidenses".
Y añadió: "Si OpenAI no puede cumplir los requisitos básicos de gobernanza de datos, transparencia, seguridad y protección, entonces sus sistemas no son aptos para el mercado europeo".
La Ley de IA podría incluir los grandes modelos lingüísticos (LLM) en una categoría de "alto riesgo
La Ley de IA de la UE define distintas categorías de IA, incluida una de "alto riesgo" sujeta a normas estrictas de transparencia y supervisión. Este parece ser el centro de los temores de Altman.
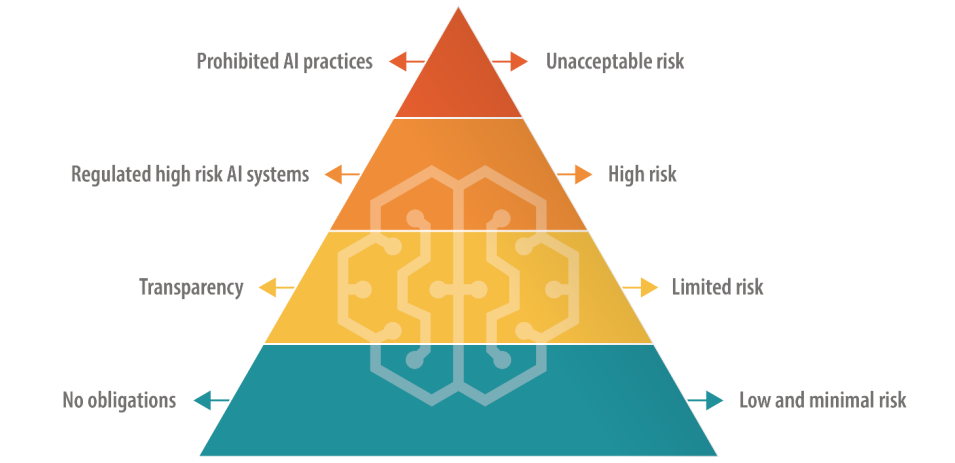
A partir del borrador actual, las empresas que desplieguen IA de alto riesgo deben revelar cualquier material protegido por derechos de autor incluido en los datos de entrenamiento y la actividad de registro para garantizar la replicabilidad y trazabilidad de los resultados. Esto podría resultar costoso y oneroso para las empresas de IA más pequeñas.
Los derechos de autor siguen siendo un escollo
OpenAI dista mucho de ser un libro abierto en lo que respecta al material protegido por derechos de autor en sus datos de entrenamiento.
Se ha comprobado que la IA repetir líneas de varias novelas, entre ellas Harry Potter y Juego de Tronos. Los investigadores sugieren esto se debe probablemente a que con frecuencia aparecen pasajes de libros en el dominio público.
Hay muchos casos judiciales pendientes relacionados con los derechos de autor contra OpenAI, Microsoft y los creadores de generadores de imágenes como A mitad de camino. Ahora mismo, simplemente desconocemos el alcance del uso que hace la IA de los datos protegidos por derechos de autor y los métodos para recuperarlos.
La UE quiere cambiar esta situación introduciendo normas de transparencia, lo que podría cambiar la forma en que se entrenan las IA y, por tanto, su rendimiento.
Puede que estemos viviendo en una burbuja de IA no regulada que está a punto de estallar.



